1. JavaScript
1. JavaScript历史
1.1. 与ECMAScript的关系
ECMAScript 是 JavaScript 语言的规范标准,JavaScript 是 ECMAScript 的一种实现。注意,这两个词在一般语境中是可以互换的。
1.2. JavaScript构成
- 核心(ECMAScript):语言核心部分。
- 文档对象模型(Document Object Model,DOM):网页文档操作标准。
- 浏览器对象模型(BOM):客户端和浏览器窗口操作基础。
2. 基础知识
2.1. 引入使用
1 在HTML中使用
在script写JavaScript代码,为 <script> 标签设置type=”text/javascript”属性
<script type="text/javascript">
document.write("<h1>Hi,JavaScript!</h1>");
</script>2. 使用单独的JavaScript文件
JavaScript的文件后缀为.js
js文件不能单独使用,需要导入到网页中,通过浏览器执行,导入也是使用<script>标签,type属性不变,src属性值为js文件的路径
注意:使用<script>标签包含外部 JavaScript 文件时,默认文件类型为 Javascript。因此,不管加载的文件扩展名是不是 .js,浏览器都会按 JavaScript 脚本来解析。
定义 src 属性的<script> 标签不应再包含 JavaScript 代码。如果嵌入了代码,则只会下载并执行外部 JavaScript 文件,嵌入代码将被忽略。
3. 文件延迟和异步加载
由于html文件加载的循序性,<script>标签会被放在head里面。如此,浏览器会首先加载js文件,只有等js代码被加载、解析、执行完毕之后才会解析html文件,如果js文件过大html解析就容易产生”滞后“,这种效应就被称为”阻塞效应“。所以建议将JavaScript文件放在head标签后面
1. 延迟执行JavaScript文件
<script>标签有一个布尔型属性 defer,设置该属性能够将 JavaScript 文件延迟到页面解析完毕后再运行。
<script type="text/javascript" defer src="test.js"></script>注意:defer 属性适用于外部 JavaScript 文件,不适用于 <script>签包含的 JavaScript 脚本。
2. 异步加载JavaScript文件
现在可以为 <script> 标签设置 async 属性,让浏览器异步加载 JavaScript 文件,即在加载 JavaScript 文件时,浏览器不会暂停,而是继续解析。这样能节省时间,提升响应速度。
<script type="text/javascript" async src="test.js"></script>async 是 HTML5 新增的布尔型属性,通过设置 async 属性,就不用考虑 <script> 标签的放置位置,用户可以根据习惯继续把很多大型 JavaScript 库文件放在 <head> 标签内。
4. JavaScript字符编码
JavaScript 遵循 Unicode 字符编码规则(可以使用中文,但不建议)。
由于 JavaScript 脚本一般都嵌入在网页中,并最终由浏览器来解释,因此在考虑到 JavaScript 字符编码的同时, 还要兼顾 HTML 文档的字符编码,以及浏览器支持的编码。一般建议保持 HTML 文档的字符编码与 JavaScript 字符编码一致,以免出现乱码。
2.2. 语句
尽管大多数的时候,当换行符存在的时候可以省略分号,但是仍然有少部分的情况下会引起未知的错误。
alert("There will be an error")
[1, 2].forEach(alert)
// 实际解析
alert("There will be an error")[1, 2].forEach(alert)1. JavaScript代码块
不同script标签下的代码块由于加载的顺序性,只有等上一个代码块加载、解析、执行完毕之后才会加载下一个代码块。尽管如此不同的代码块仍属于相同的作用域(全局作用域)。
例如:以下代码会出现错误
<script>
//JavaScript 代码块 1
alert(a);
</script>
<script>
//JavaScript 代码块 2
var a = 1;
</script>而以下却不会
<script>
//JavaScript 代码块 2
var a = 1;
</script>
<script>
//JavaScript 代码块 1
alert(a);
</script>2. 注释
- 单行注释://单行注释信息。
- 多行注释:/*多行注释信息*/
3. 严格模式
ECMAscript5 新增了严格运行模式。推出严格模式的目的如下:
- 消除 JavaScript 语法中不合理、不严谨的用法。
- 消除代码运行的一些安全隐患。
- 提高编译器效率,提升程序运行速度。
- 为未来新版本的规范化做好铺垫。
一旦启用严格模式,那么开弓没有回头箭
1. 启用严格模式
"use strict"
// 必须在首部中使用,否则视为无效。所谓首部就是前面没有任何有效js代码不支持严格模式的浏览器会把它作为字符串直接量忽略掉。
2. 严格模式的应用场景
==全局模式==
将 “use strict” 放在脚本文件的第一行,则整个脚本都将以严格模式运行。如果不在第一行,则整个脚本将以正常模式运行。
在不同<script>代码块中并不是互通的,即第一个<script>代码块启用,第二个<script>代码块并不会生效
==局部模式==
function strict(){
"use strict";
return "这是严格模式。";
}
function notStrict(){
return "这是正常模式。";
}全局模式不利于 JavaScript 文件合并。例如,如果一个开启了严格模式的 JavaScript 库,被导入到一个正常模式的网页脚本中,由于无法确保 “use strict” 位于脚本的首部位置,容易导致严格模式失效。因此,推荐的最佳实践是使用局部模式,将整个 JavaScript 文件脚本放在一个立即执行的匿名函数中,在匿名函数内启动严格模式。当 JavaScript 库文件被导入到不同模式的网页中,就不用担心严格模式失效了。
(function(){
"use strict";
// JavaScript库文件 代码
}) ();2.3. 变量
在非严格模式下,JavaScript 允许不声明变量就直接为其赋值,这是因为 JavaScript 解释器能够自动隐式声明变量。隐式声明的变量总是作为全局变量使用。在严格模式下,变量必须先声明,然后才能使用。
变量提升:JavaScript 在预编译期会先预处理声明的变量,但是变量的赋值操作发生在 JavaScript 执行期,而不是预编译期。
let不会进行声明提升 ! !会直接发生编译错误
1. 变量作用域
- 全局变量:变量在整个页面脚本中都是可见的,可以被自由访问。
- 在任何函数体外直接使用 var 语句声明。
- 直接添加属性到全局对象上。在 Web 浏览器中,全局作用域对象为 window。
- 直接使用未经声明的变量,以这种方式定义的全局变量被称为隐式的全局变量。
- 局部变量:变量仅能在声明的函数内部可见,函数外是不允许访问的。
2. 变量污染
全局变量在全局作用域内都是可见的,因此具有污染性。大量使用全局变量会降低程序的可靠性,用户应该避免使用全局变量。
解决方法:
在脚本中创建一个全局变量,作为当前应用的唯一接口,然后通过对象直接量的形式包含所有应用程序变量。
var MyAPP = {}; //定义 APP 访问接口
MyAPP.name = { //定义APP配置变量
"id" : "应用程序的ID编号"
};
MyAPP.work = {
num : 123, //APP计数器等内部属性
sub : { name : "sub_id"}, //APP应用分支
doing : function(){ //具体方法
//执行代码
}
};把应用程序的所有变量都追加在该唯一名称空间下,降低与其他应用程序相互冲突的概率,应用程序也会变得更容易阅读。
使用函数体封装应用程序,这是最常用的一种方法。
(function(window){
var MyAPP = {}; //定义 APP 访问接口
MyAPP.name = { //定义APP配置变量
"id" : "应用程序的ID编号"
};
MyAPP.work = {
num : 123, //APP计数器等内部属性
sub : { name : "sub_id"}, //APP 应用分支
doing : function(){ //具体方法
//执行代码
}
};
window.MyAPP; //对外开放应用程序接口
})(window)在 JavaScript 函数体内,所有声明的私有变量、参数、内部函数对外都是不可见的,如果不主动开放,外界是无法访问内部数据的,因此使用函数体封装应用程序是最佳实践。
使用var可以重复声明,但是let无法重复声明
变量尽量进行
新建而非重用,看起来这存在性能丢失,但是现代编译器经过优化基本上不会产生性能问题。另外新建的最大好处是不用担心它在其它地方被更改而遗忘造成以后调试的困难。
3. 常量
关键字”const“,常量的命名尽量使用大写
2.4. 数据类型
- 简单的值(原始值):包含字符串、数字和布尔值,此外,还有两个特殊值——null(空值)和 undefined(为定义)。
- 复杂的数据结构(泛指对象):包括狭义的对象、数组和函数。
使用typeof运算符可以查看值的数据类型
注意:
- 把 null 归为 Object 类型,而不是作为一种特殊类型(Null)的值。
- 把 function(,){} 归为 Function 类型。即把函数视为一种独立的基本数据类型,而不是 Object 类型的一种特殊子类。
在 JavaScript 中,函数是一种比较特殊的结构。它可以是一段代码集合,也可以是一种数据类型;可以作为对象来使用,还可以作为构造函数创建类型。JavaScript 函数的用法比较灵活,这也是 JavaScript 语言敏捷的一种表现(函数式编程)。
1. Number
除了常规的数字外还有一些”特殊数值“:
- Infinity:无穷大,可以通过除法获得也可以使用该关键字
- -Infinity:
- NaN:代表计算错误,一个不正确或未定义的数学操作所获得的结果,例如字符串除以数字
typeof 不能分辨数字和 NaN,并且 NaN 不等同于它自己。
NaN === NaN //false
NaN !== NaN //true使用 isNaN() 全局函数可以判断 NaN。
使用 isFinite() 全局函数可以判断 NaN 和 Infinity
| 特殊值 | 说明 |
|---|---|
| Infinity | 无穷大。当数值超过浮点型所能够表示的范围;反之,负无穷大为-Infinity |
| NaN | 非数值。不等于任何数值,包括自己。如当0除以0时会返回这个特殊值 |
| Number.MAX_VALUE | 表示最大数值 |
| Number.MIN_VALUE | 表示最小数值,一个接近0的值 |
| Number.NaN | 非数值,与NaN常量相同 |
| Number.POSITIVE_INFINITY | 表示正无穷大的数值 |
| Number.NEGATIVE_INFINITY | 表示负无穷大的数值 |
NaN(Not a Number,非数字值)是在 IEEE 754 中定义的一个特殊的数值。
当试图将非数字形式的字符串转换为数字时,就会生成 NaN。
当 NaN 参与数学运算时,运算结果也是 NaN。
因此,可以使用它来检测 NaN、正负无穷大。如果是有限数值,或者可以转换为有限数值,那么将返回 true。如果只是 NaN、正负无穷大的数值,则返回 false 。
数学运算时永远安全的
2. BigInt
可以通过将 n 附加到整数字段的末尾来创建 BigInt 值。
不可以将BigInt和常规数字类型进行计算
alert(1n + 2); // Error: Cannot mix BigInt and other types这也就意味着我们无法对其使用一元加法
注意number和BigInt属于不同类型
3. String类型
在 JavaScript 中,有三种包含字符串的方式。
- 双引号:
"Hello". - 单引号:
'Hello'. - 反引号:
Hello.
双引号和单引号都是“简单”引用,在 JavaScript 中两者几乎没有什么差别。
反引号是 功能扩展 引号。它们允许我们通过将变量和表达式包装在 ${…} 中,来将它们嵌入到字符串中。
JavaScript 中没有 character 类型。
4. 布尔类型
在 JavaScript 中,undefined、null、””、0、NaN 和 false 这 6 个特殊值转换为布尔值时为 false,被称为假值。除了假值以外,其他任何类型的数据转换为布尔值时都是 true。
注意在使用
Boolean判断时任何非空字符串都是true包含‘0’
5. null
相比较于其他编程语言,JavaScript 中的 null 不是一个“对不存在的 object 的引用”或者 “null 指针”。
JavaScript 中的 null 仅仅是一个代表“无”、“空”或“值未知”的特殊值。
6. undefined
undefined的含义表示未被赋值,使用typeof判断null返回object,这是官方承认的一个错误,实际上null是一个自己的类型而非object
建议将null作为一个
空或者未知的变量,将undefined作为一个未进行初始化的事物
7. object和symbol
8. typeof
typeof 运算符返回参数的类型。
- 作为运算符:
typeof x。 - 函数形式:
typeof(x)。
2.5. 交互
1. alert
alert("Hello");弹出的这个带有信息的小窗口被称为 模态窗。“modal” 意味着用户不能与页面的其他部分(例如点击其他按钮等)进行交互,直到他们处理完窗口。
2. prompt
// title显示给用户的文本
// default可选,指定input的初始值
// 返回用户输入的值,为输入得到null
result = prompt(title, [default]);浏览器会显示一个带有文本消息的模态窗口,还有 input 框和确定/取消按钮。
3. confirm
result = confirm(question);confirm 函数显示一个带有 question 以及确定和取消两个按钮的模态窗口。
点击确定返回 true,点击取消返回 false
上述所有方法共有两个限制:
- 模态窗口的确切位置由浏览器决定。通常在页面中心。
- 窗口的确切外观也取决于浏览器。我们不能修改它。
2.6. 类型判断
1. typeof
2. constructor
constructor 是 Object 类型的原型属性,它能够返回当前对象的构造器(类型函数)。利用该属性,可以检测复合型数据的类型,如对象、数组和函数等。
undefined 和 null 没有 constructor 属性,不能够直接读取,否则会抛出异常。因此,一般应先检测值是否为 undefined 和 null 等特殊值,然后再调用 constructor 属性。
var value = undefined;
console.log(value && value.constructor); //返回 undefined
var value = null;
console.log(value && value.constructor); //返回 null数值直接量也不能直接读取 constructor 属性,应该先把它转换为对象再调用。
console.log(10.construetor); //抛出异常
console.log((10).constructor); //返回 Number 类型
console.log(Number(10).constructor); //返回 Number 类型3. toString
toString 是 Object 类型的原型方法,它能够返回当前对象的字符串表示。利用该属性,可以检测复合型数据的类型,如对象、数组、函数、正则表达式、错误对象、宿主对象、自定义类型对象等;也可以对值类型数据进行检测。
toString返回的字符串根据各个对象会有所不同,各个对象可能对该函数进行重写。
使用原型下的toString返回的格式就会统一
var _toString = Object.prototype.toString; //引用 Objget 的原型方法 toString ()
//使用 apply 方法在对象上动态调用 Object 的原型方法 toString ()
console.log(_toString.apply(o)); //表示为 "[object Object]"仔细发现我们会发现原型的toString返回的格式如下:
[object Class]其中,object 表示对象的基本类型,Class 表示对象的子类型,子类型的名称与该对象的构造函数名对应。例如,Object 对象的 Class 为 “Object”,Array 对象的 Class 为 “Array” , Function 对象的 Class 为 “Function”, Date 对象的 Class 为 “Date”,Math 对象的 Class 为 “Math”,Error 对象(包括 Error 子类)的 Class 为 “Error” 等。
2.7. 类型转换
1. 转换为字符串
1. 使用加号运算符
- 把数字转换为字符串,返回数字本身。
- 把布尔值转换为字符串,返回字符串 “true” 或 “false”。
- 把数组转换为字符串,返回数组元素列表,以逗号分隔。如果是空数组,则返回空字符串。
- 把函数转换为字符串,返回函数的具体代码字符串。
- 如果是内置类型函数,则只返回构造函数的基本结构,省略函数的具体实现代码。而自定义类型函数与普通函数一样,返回函数的具体实现代码字符串。
- 如果是内置静态函数,则返回 [object Class] 格式的字符串表示。
- 如果把对象实例转换为字符串,则返回的字符串会根据不同类型或定义对象的方法和参数而不同。
- 对象直接量,则返回字符串为 “[object object]”
- 如果是自定义类的对象实例,则返回字符串为 “[object object]”。
- 如果是内置对象实例,具体返回字符串将根据参数而定。
加号运算符有两个计算功能:数值求和、字符串连接。但是字符串连接操作的优先级要大于求和运算。因此,在可能的情况下,即运算元的数据类型不一致时,加号运算符会尝试把数值运算元转换为字符串,再执行连接操作。
2. 使用toString
当为简单的值调用 toString() 方法时,JavaScript 会自动把它们封装为对象,然后再调用 toString() 方法,获取对象的字符串表示。
使用加号运算符转换字符串,实际上也是调用 toString() 方法来完成,只不过是 JavaScript 自动调用 toString() 方法实现的。
JavaScript 能够根据运算环境自动转换变量的类型。在自动转换中,JavaScript 一般根据运算的类型环境,按需进行转换。例如,如果在执行字符串为字符串;如果在执行基本数学运算,则会尝试把字符串转换为数值;如果在逻辑运算环境中,则会尝试把值转换为布尔值等。
2. 转换为数字模式字符串
toString() 是 Object 类型的原型方法,Number 子类继承该方法后,重写了 toString(),允许传递一个整数参数,设置显示模式。数字默认为十进制显示模式,通过设置参数可以改变数字模式。
toString() 方法能够直接输出整数和浮点数,保留小数位。小数位末尾的零会被清除。但是对于科学计数法,则会在条件许可的情况下把它转换为浮点数,否则就用科学计数法形式输出字符串。
在默认情况下,无论数值采用什么模式表示,toString() 方法返回的都是十进制的数字字符串。因此,对于八进制、二进制或十六进制的数字,toString() 方法都会先把它们转换为十进制数值之后再输出。
如果设置参数,则 toString() 方法会根据参数把数值转换为对应进制的值之后,再输出为字符串表示。
var a = 10; //十进制数值 10
console.log(a.toString(2)); //返回二进制数字字符串“1010”
console.log(a.toString(8)); //返回八进制数字字符串“12”
console.log(a.toString(16)); //返回十六进制数字字符串“a”3. 转换为小数格式字符串
由于toString在小数转换时会抹掉末尾的0,这对某些领域是极为不便的
1. toFixed()
toFixed() 能够把数值转换为字符串,并显示小数点后的指定位数。默认为0
2. toExponential()
toExponential() 方法专门用来把数字转换为科学计数法形式的字符串,toExponential() 方法的参数指定了保留的小数位数。省略部分采用四舍五入的方式进行处理。
var a = 123456789;
console.log(a.toExponential(2)); //返回字符串“1.23e+8”
console.log(a.toExponential(4)); //返回字符串“1.2346e+8”3. toPrecision()
toPrecision() 方法与 toExponential() 方法相似,但它可以指定有效数字的位数,而不是指定小数位数。
var a = 123456789;
console.log(a.toPrecision(2)); //返回字符串“1.2e+8”
console.log(a.toPrecision(4)); //返回字符串“1.235e+8”4. 转换为数字
| 1 | 1 |
|---|---|
| 0 | 0 |
| true | 1 |
| false | 0 |
| “” | 0 |
| undefined | NaN |
| null | 0 |
| NaN | NaN |
| Infinity | Infinity |
1. parseInt()
从左至右依次解析字符串,若遇到非数字则停止,最后结果没有数字就返回NaN
console.log(parseInt("123abc")); //返回数字123
console.log(parseInt("1.73")); //返回数字1
console.log(parseInt(".123")); //返回值NaN如果是以 0 开头的数字字符串,则 parseInt() 会把它作为八进制数字处理:先把它转换为八进制数值,然后再转换为十进制的数字返回。
如果是以 0x 开头的数字字符串,则 parseInt() 会把它作为十六进制数字处理:先把它转换为十六进制数值,然后再转换为十进制的数字返回。
parseInt() 也支持基模式(设置数值为指定进制,但是都返回十进制),可以把二进制、八进制、十六进制等不同进制的数字字符串转换为整数。基模式由 parseInt() 函数的第二个参数指定。
2. parseFloat()
parseFloat() 也是一个全局方法,它可以把值转换为浮点数,即它能够识别第一个出现的小数点,而第二个小数点被视为非法。解析过程与 parseInt() 方法相同。
parseFloat() 的参数必须是十进制形式的字符串,而不能使用八进制或十六进制的数字字符串。同时,对于数字前面的 0(八进制数字标识)会忽略,对于十六进制的数字将返回 0。
3. 使用乘号运算符
如果变量乘以 1,则变量会被 JavaScript 自动转换为数值。乘以 1 之后,结果没有发生变化,但是值的类型被转换为数值。如果值无法被缓缓为合法的数值,则返回 NaN。
5. 转换为布尔值
| 1 | true |
|---|---|
| 0 | false |
| true | true |
| false | false |
| “” | false |
| undefined | false |
| null | false |
| NaN | false |
| Infinity | true |
- 使用双重逻辑非:!!
- 使用Boolean()函数
6. 转换为对象
类似java的包装器
console.log(typeof new String(n)); //返回Object
console.log(typeof new Number(n)); //返回Object
console.log(typeof new Boolean(n)); //返回Object7. 转换为简单值
==//TODO==
2.8. 基础运算
1. 加法运算
特殊操作数的求和运算
var n = 5; //定义并初始化任意一个数值
console.log(NaN + n); //NaN与任意操作数相加,结果都是NaN
console.log(Infinity + n); //Infinity与任意操作数相加,结果都是Infinity
console.log(Infinity + Infinity); //Infinity与Infinity相加,结果是Infinity
console.log((-Infinity) + (-Infinity)); //负Infinity相加,结果是负Infinity
console.log((-Infinity) + Infinity); //正负Infinity相加,结果是NaN2. 减法运算
特殊操作数的减法运算
var n = 5; //定义并初始化任意一个数值
console.log(NaN - n); //NaN与任意操作数相减,结果都是NaN
console.log(Infinity - n); //Infinity与任意操作数相减,结果都是Infinity
console.log(Infinity - Infinity); //Infinity与Infinity相减,结果是NaN
console.log((-Infinity) - (-Infinity)); //负Infinity相减,结果是NaN
console.log((-Infinity) - Infinity); //正负Infinity相减,结果是-Infinity使用值减去 0,可以快速把值转换为数字。例如 HTTP 请求中查询字符串一般都是字符串型数字,可以先把这些参数值减去 0 转换为数值。这与调用 parseFloat() 方法的结果相同,但减法更高效、快捷。减法运算符的隐性转换如果失败,则返回 NaN,这与使用 parseFloat() 方法执行转换时的返回值是不同的。
对于字符串减法必须是完整的数字字符串否则会返回NaN
对于布尔值来说,parseFloat() 方法能够把 true 转换为 1,把 false 转换为 0,而减法运算符视其为 NaN。
对于对象来说,parseFloat() 方法会尝试调用对象的 toString() 方法进行转换,而减法运算符先尝试调用对象的 valueOf() 方法进行转换,失败之后再调用 toString() 进行转换。
3. 乘法运算
特殊操作数的乘法运算
var n = 5; //定义并初始化任意一个数值
console.log(NaN * n); //NaN与任意操作数相乘,结果都是NaN
console.log(Infinity * n); //Infinity与任意非零正数相乘,结果都是Infinity
console.log(Infinity * (- n)); //Infinity与任意非零负数相乘,结果是-Infinity
console.log(Infinity * 0); //Infinity与0相乘,结果是NaN
console.log(Infinity * Infinity); //Infinity与Infinity相乘,结果是Infinity4. 除法运算
特殊操作数的除法运算
var n = 5; //定义并初始化任意一个数值
console.log(NaN / n); //如果一个操作数是NaN,结果都是NaN
console.log(Infinity / n); //Infinity被任意数字除,结果是Infinity或-Infinity
//符号由第二个操作数的符号决定
console.log(Infinity / Infinity); //返回NaN
console.log(n / 0); //0除一个非无穷大的数字,结果是Infinity或-Infinity,符号由第二个操作数的符号决定
console.log(n / -0); //返回-Infinity,解释同上5. 求余运算
6. 取反运算
特殊操作数的取反运算
console.log(- 5); //返回-5。正常数值取负数
console.log(- "5"); //返回-5。先转换字符串数字为数值类型
console.log(- "a"); //返回NaN。无法完全匹配运算,返回NaN
console.log(- Infinity); //返回-Infinity
console.log(- (- Infinity)); //返回Infinity
console.log(- NaN); //返回NaN7. 递增递减运算
递增和递减是相反的操作,在运算之前都会试图转换值为数值类型,如果失败则返回 NaN。
8. 链式赋值
let a, b, c;
a = b = c = 2 + 2;9. 逗号运算符
逗号运算符能让我们处理多个语句,使用 , 将它们分开。每个语句都运行了,但是只有最后的语句的结果会被返回。
let a = (1 + 2, 3 + 4);
alert( a ); // 7(3 + 4 的结果)10. 大小比较
比较运算中的操作数可以是任意类型的值,但是在执行大小运算时,会被转换为数字或字符串,然后再进行比较。如果是数字,则比较大小;如果是字符串,则根据字符编码表中的编号值从左到右逐个比较每个字符。
如果一个操作数是数字,或者被转换为数字,另一个是字符串,或者被转换为字符串,则使用 parseInt() 将字符串转换为数字(对于非数字字符串,将被转换为 NaN),最后以数字方式进行比较。
如果一个操作数为 NaN,或者被转换为 NaN,则始终返回 false。
如果一个操作数是对象,则先使用 valueOf() 取其值,再进行比较;如果没有 valueOf() 方法,则使用 toString() 取其字符串表示,再进行比较。
如果一个操作数是布尔值,则先转换为数值,再进行比较。
如果操作数都无法转换为数字或字符串,则比较结果为 false。
字符比较是区分大小写的,一般小写字符大于大写字符。如果不区分大小写,则建议使用 toLowerCase() 或 toUpperCase() 方法把字符串统一为小写或大写形式之后再比较。
==为了设计可控的比较运算,建议先检测操作数的类型,主动转换类型。==
==奇怪的结果:==
alert( null > 0 ); // (1) false
alert( null == 0 ); // (2) false
alert( null >= 0 ); // (3) true这是因为在执行==检查和><>=<=检查的处理逻辑并不相同。
undefined 和 null 在相等性检查 == 中不会进行任何的类型转换,它们有自己独立的比较规则,所以除了它们之间互等外,不会等于任何其他的值。
==特殊的undefined==
alert( undefined > 0 ); // false (1)
alert( undefined < 0 ); // false (2)
alert( undefined == 0 ); // false (3)总结
undefined和null在与其它内容==判断下会转换为NaN,如果两者相互判断则相等。
2.9 ‘??’和’||’
1. 空值合并运算符‘??’
a ?? b 的结果是:
- 如果
a是已定义的,则结果为a, - 如果
a不是已定义的,则结果为b。
这里的已定义是指非undefined和null
它与||和&&区别就是:
||返回第一个 真 值。??返回第一个 已定义的 值。&&返回第一个假值
这三种运算符可以连续使用,但出于安全原因,JavaScript 禁止将
??运算符与&&和||运算符一起使用,除非使用括号明确指定了优先级。这三种运算符都属于短路运算符
2.10. 函数
一个函数是一个行为,所以函数名通常是动词。
目前有许多优秀的函数名前缀,如 create…、show…、get…、check… 等等。使用它们来提示函数的作用吧。
1. 变量
函数对外部变量拥有全部的访问权限,如果在函数内部声明了同名变量,那么函数会遮蔽外部变量。
2. 参数
如果未提供参数,那么其默认值则是 undefined。
// 第二个参数有默认值
function showMessage(from, text = "no text given") {
alert( from + ": " + text );
}作为参数传递给函数的值,会被复制到函数的局部变量。
3. 返回值
空值的 return 或没有 return 的函数返回值为 undefined
空值的 return 和 return undefined 等效:
不要在
return与返回值之间添加新行。因为 JavaScript 默认会在return之后加上分号
return // 会在后面默认加一个”;“
(some + long + expression + or + whatever * f(a) + f(b))4. 函数表达式
// 函数声明
function sayHi() {
alert( "Hello" );
}
// 函数表达式,所以末尾有一个分号
let sayHi = function() {
alert( "Hello" );
};
// 将函数本身赋值到a中
let a=sayHi;
// 可以正常像sayHi()一样调用
a();
// 将函数的值赋值给b
let b=sayHi();
严格模式下,当一个函数声明在一个代码块内时,它在该代码块内的
任何位置都是可见的。但在代码块外不可见。
5. 回调函数
function ask(question, yes, no) {
if (confirm(question)) yes()
else no();
}ask传入yes和no两个回调函数,如果question为真,则调用yes,反之调用no
6. 箭头函数
let func = (arg1, arg2, ...argN) => expression
// 等同于下面的表达式
let func = function(arg1, arg2, ...argN) {
return expression;
};
// 多行箭头函数,需要return
let func = (arg1, arg2, ...argN) => {
return expression
}普通函数中,是包含this的,只是可能this的指向为undefined,而在箭头函数中,它没有this,如果缺少它会像变量一样在外部的词法环境中查找。
不具有
this自然也就意味着另一个限制:箭头函数不能用作构造器(constructor)。不能用new调用它们。
箭头函数没有
arguments对象。
箭头函数没有
super
3. Object(对象):基础知识
3.1. 对象
1. 对象创建
// “构造函数” 的语法
let user = new Object();
// “字面量” 的语法
let user = {
name: "John",
age: 30,
"likes birds": true , // 最后一个属性建议用逗号结尾(尾随、悬挂逗号)
};
console.log(user["likes birds"]); // true
console.log(user.name); //John2. 属性删除
delete user.age;3. 属性修改
使用
const声明的对象是可以被修改的,const声明仅固定了user的值,而不是值(该对象)里面的内容。
4. 计算属性
let fruit = prompt("Which fruit to buy?", "apple");
let bag = {
[fruit]: 5, // 属性名是从 fruit 变量中得到的
};
alert( bag.apple ); // 5 如果 fruit="apple"属性名称可以与系统保留字重复,并且任何非字符串类型作为对象键时都会转换为字符串
5. 属性存在:in
let user = { name: "John", age: 30 };
alert( "age" in user ); // true,user.age 存在除了in关键字外还可以使用undefined判断,但是它有一定的局限性,比如该属性的值本身就是undefined
6. 属性遍历:for in
for (let key in user) {
// keys
alert( key ); // name, age, isAdmin
// 属性键的值
alert( user[key] ); // John, 30, true
}3.2. 对象引用和复制
1. 对象比较
只有当两个对象的引用指向同一个内存区域才会相等
let a = {};
let b = {}; // 两个独立的对象
alert( a == b ); // false2. 克隆与合并:Object.assign
由于直接复制只是复制引用而非对象,可以使用迭代来将属性挨个复制到新对象中。或者使用Object.assign快速克隆:
// 将src1、src2...的属性复制到dest对象中,若有相同的属性则会进行内容的覆盖
Object.assign(dest, [src1, src2, src3...])Object.assign只能浅克隆,可以使用 JavaScript 库 lodash 中的 _.cloneDeep(obj)完成深克隆
3.3. this
在 JavaScript 中,this 关键字与其他大多数编程语言中的不同。JavaScript 中的 this 可以用于任何函数,即使它不是对象的方法。例如:
function sayHi() {
alert( this.name );
}
// 若sayHi没有分配给任意对象,则在严格模式下指向undefined,普通模式下指向全局对象(window)
this的值是在代码运行时计算出来的,它取决于代码上下文。
箭头函数没有自己的
this,它取决于外部正常的函数
3.4. 构造器和操作符“new”
function User(name) {
this.name = name;
this.isAdmin = false;
}
let user = new User("Jack");
alert(user.name); // Jack
alert(user.isAdmin); // false若没有参数可以省略括号,建议不要使用
一般情况下构造函数没有
return,如果有若返回普通类型则忽略,返回对象则构造出来的对象即为返回的对象。
3.5. 可选链“?.”
如果可选链 ?. 前面的部分是 undefined 或者 null,它会停止运算并返回该部分。
let user = {}; // user 没有 address 属性
alert( user?.address?.street ); // undefined(不报错)
?.最开始的变量必须已声明,否则会触发错误
?.()调用一个可能不存在的函数,?.[]调用类中可能不存在的属性,可以和delete配合使用删除一个可能不存在的属性
3.6. Symbol
Symbol 是唯一标识符的基本类型,Symbol 保证是唯一的。即使我们创建了许多具有相同描述的 Symbol,它们的值也是不同。描述只是一个标签,不影响任何东西。
// id1的描述为id
let id1 = Symbol("id");
let id2 = Symbol("id");
alert(id1 == id2); // falseSymbol不会被自动转换为字符串,可以通过
toString或者description来获取描述
可以使用 Symbol 作为键来访问或计算属性类中数据
user[id],作为类中的键会被隐藏属性,无法通过for in迭代出来,只能通过[]访问,但这并不觉得js提供了相关方法来进行Symbol访问迭代
let a = Symbol('age')
user = {
username: 'john',
[a]: '18',
}
// 无法使用user[age]
console.log(user[a])全局Symbol注册表
// 从全局注册表中读取
let id = Symbol.for("id"); // 如果该 Symbol 不存在,则创建它
// 再次读取(可能是在代码中的另一个位置)
let idAgain = Symbol.for("id");
// 相同的 Symbol
alert( id === idAgain ); // trueSymbol.keyFor:通过Symbol来反向获取它的描述,只适合用于全局Symbol,非全局会返回undefined
// 通过 name 获取 Symbol
let sym = Symbol.for("name");
let sym2 = Symbol.for("id");
// 通过 Symbol 获取 name
alert( Symbol.keyFor(sym) ); // name
alert( Symbol.keyFor(sym2) ); // id3.7 对象–原始值转换
- 所有的对象在布尔上下文(context)中均为
true。 - 数值转换发生在对象相减或应用数学函数时,如两个
Date对象的加减。 - 字符串的转换
4. 数据类型
4.1. 原始类型
原始类型是一种值,不同于对象。
在 JavaScript 中有 7 种原始类型:
string,number,bigint,boolean,symbol,null和undefined。
一些原始对象有与之对应的
包装器类型,它们与之对应的构造器仅供内部使用,不建议使用构造器创建对象(new),利用非new创建却是完全有效的。
null/undefined 没有任何方法
4.2. 数字类型
1. 科学计数
1.23e6 = 1.23 * 1000000
1e-6 = 0.0000012. 数字调用函数
123456..toString(36) // 将数字123456按照36进制输出3. 舍入
- Math.floor:向下舍入
- Math.ceil:向上舍入
- Math.round:向最近的整数舍入
- Math.trunc(IE不支持):小数点后直接截断
4. 小数格式化
toFixed(num):仅保存到小数点后num位,超出长度填零,少于长度则按照Math.round的方式舍入,返回的是字符串。
5. Object.is
Object.is(NaN,NaN)=== true
Object.is(0,-0)=== false
// 在所有其他情况下,Object.is(a,b) 与 a === b 相同。5. parseInt和parseFloat
它们可以从字符串中“读取”数字,直到无法读取为止。
alert( parseFloat('12.5em') ); // 12.5
alert( parseFloat('12.3.4') ); // 12.3,在第二个点出停止了读取
alert( parseInt('a123') ); // NaN,第一个符号停止了读取parseInt的第二个参数指定了按照什么进制解析
6. 其它数学函数
Math.random():返回一个从 0 到 1 的随机数(不包括 1)Math.max(a,b,c...)/Math.min(a, b, c...):从任意数量的参数中返回最大/最小值。Math.pow(n, power):返回 n 的给定(power)次幂
4.3. 字符串
1. 字符串长度
length属性表示字符串长度,注意不是length函数
// "\n"长度为1
alert( `My\n`.length ); // 32. 字符串访问
[]访问charAt()访问for..of访问
[]没找到返回undefined,charAt没找到返回空字符串
字符串是不可改变的!
toUpperCase/toLowerCase返回的是一个新的字符串
3. 查找字符串
str.indexOf
如果没有找到,则返回 -1,否则返回匹配成功的位置,第二个参数可以指定查找起始位置。
str.lastIndexOf(substr, pos)
与str.indexOf类似,但是这是从后至前查找。
4. 按位(bitwise)NOT 技巧
对于 32-bit 整数,~n 等于 -(n+1)。则有n=-1时,得到的结果才会为0
let str = "Widget";
if (~str.indexOf("Widget")) {
alert( 'Found it!' ); // 正常运行
}只有旧代码才会发现那些内容,现在都提供了相关的方法
5. includes,startsWith,endsWith
alert( "Widget with id".includes("Widget") ); // true
alert( "Midget".includes("id", 3) ); // false, 从位置 3 开始没有 "id"
alert( "Widget".startsWith("Wid") ); // true,"Widget" 以 "Wid" 开始
alert( "Widget".endsWith("get") ); // true,"Widget" 以 "get" 结束6. 获取子字符串
str.slice(start [, end])
返回字符串从 start 到(但不包括)end 的部分,如果没有第二个参数,slice 会一直运行到字符串末尾。
start和end可以是负值
str.substring(start [, end])
这与 slice 几乎相同,但它允许 start 大于 end。不支持负参数(不像 slice),它们被视为 0。
let str = "stringify";
alert( str.substring(6, 2) ); // "ring"str.substr(start [, length])
与以前的方法相比,这个允许我们指定 length 而不是结束位置。
4.4. 数组
1. 作用于数组末端的方法
pop取出并返回数组的最后一个元素
push在数组末端添加元素
2. 作用于数组首端的方法
shift取出数组的第一个元素并返回它
unshift在数组的首端添加元素
数组误用的几种方式:
- 添加一个非数字的属性,比如
arr.test = 5。 - 制造空洞,比如:添加
arr[0],然后添加arr[1000](它们中间什么都没有)。 - 以倒序填充数组,比如
arr[1000],arr[999]等等。
以上的使用都会让其关闭内部的数组优化
for in与for of:
- for in会迭代所有属性,适用于普通对象,除了数组
- for of适合数组迭代
3. 清空数组
arr.length = 04. 多维数组
let matrix = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
];5. toString
数组元素以“,”进行分割
alert( [1,2] + 1 ); // "1,21"6. splice
由于数组属于对象,所以也可以使用delete关键字,但是数组长度并不会变,这个位置的值变成了undefined
splcie像一把瑞士军刀,可以做添加、删除、插入元素。
arr.splice(start[, deleteCount, elem1, ..., elemN])从start开始删除deleteCount个元素并用elm1…elmN进行替代,然后返回被删除的元素。如果deleteCount=0就变成了插入元素
7. slice
arr.slice([start], [end])它会返回一个新数组,将所有从索引 start 到 end(不包括 end)的数组项复制到一个新的数组。start 和 end 都可以是负数,在这种情况下,从末尾计算索引。缺省第二值就是截取到尾端。
8. concat
arr.concat(arg1, arg2...)创建一个新数组,其中包含来自于其他数组和其他项的值,它接受任意数量的参数 —— 数组或值都可以。
9. forEach
arr.forEach(function(item, index, array) {
// ... do something with item
});10. indexOf/lastIndexOf 和 includes
和字符串相似只是作用于数组上。注意内部比较使用的是严格相等===
11. find 和 findIndex
主要针对对象数组:
let result = arr.find(function(item, index, array) {
// 如果返回 true,则返回 item 并停止迭代
// 对于假值(falsy)的情况,则返回 undefined
});如果它返回 true,则搜索停止,并返回 item。如果没有搜索到,则返回 undefined。
arr.findIndex 方法s(与 arr.find 方法)基本上是一样的,但它返回找到元素的索引,而不是元素本身。并且在未找到任何内容时返回 -1。
12. filter
语法与 find 大致相同,但是 filter 返回的是所有匹配元素组成的数组
let results = arr.filter(function(item, index, array) {
// 如果 true item 被 push 到 results,迭代继续
// 如果什么都没找到,则返回空数组
});13. map
它对数组的每个元素都调用函数,并返回结果数组。
let result = arr.map(function(item, index, array) {
// 返回新值而不是当前元素
})14. sort(fn)
arr.sort 方法对数组进行 原位(in-place) 排序,更改元素的顺序。
这些元素默认情况下被按字符串进行排序。传入一个比较器来进行手动排序,比较器返回正数为大于,负数为小于。
15. reverse
arr.reverse 方法用于颠倒 arr 中元素的顺序。
16. split与join
split以指定符号进行字符串分割为数组,join以指定符号将数组拼接成字符串
17. reduce/reduceRight
该函数一个接一个地应用于所有数组元素,并将其结果“搬运(carry on)”到下一个调用,然后返回最终的结果
let value = arr.reduce(function(accumulator, item, index, array) {
// ...
}, [initial]);accumulator是上一个函数调用的结果,第一个为initial如果有的话,没有为0。
数组为空,并且没有初始值会出现error,所以建议传入初始值
18. Array.isArray
由于数组属于对象,所以typeof无法区分对象和数组,所以使用Array.isArray进行区分。
19. thisArg
arr.find(func, thisArg);
arr.filter(func, thisArg);
arr.map(func, thisArg);
// ...
// thisArg 是可选的最后一个参数除了sort都可以接受一个thisArg参数。
thisArg的值为this,该this和func中的this指向相同,作用主要用于上下文传递。未指定该参数则该参数等于undefined
4.5. 可迭代对象
对于那些看来像数组一样的对象,让其可以使用for of进行迭代
1. Symbol.iterator
let range = {
from: 1,
to: 5
};
// 1. for..of 调用首先会调用这个:
range[Symbol.iterator] = function() {
// ……它返回迭代器对象(iterator object):
// 2. 接下来,for..of 仅与此迭代器一起工作,要求它提供下一个值
return {
current: this.from,
last: this.to,
// 3. next() 在 for..of 的每一轮循环迭代中被调用
next() {
// 4. 它将会返回 {done:.., value :...} 格式的对象
if (this.current <= this.last) {
return { done: false, value: this.current++ };
} else {
return { done: true };
}
}
};
};
// 现在它可以运行了!
for (let num of range) {
alert(num); // 1, 然后是 2, 3, 4, 5
}字符串是可迭代对象
2. 可迭代和类数组
- 可迭代:实现
Symbol.iterator方法的对象 - 类数组:是有索引和
length属性的对象,所以它们看起来很像数组。
3. Array.from
有一个全局方法 Array.from 可以接受一个可迭代或类数组的值,并从中获取一个“真正的”数组,返回的是一个新的数组对象。
Array.from(obj[, mapFn, thisArg])可选的第二个参数 mapFn 可以是一个函数,该函数会在对象中的元素被添加到数组前,被应用于每个元素,此外 thisArg 允许我们为该函数设置 this。
// 求每个数的平方
let arr = Array.from(range, num => num * num);
alert(arr); // 1,4,9,16,25还可以像slice一样将字符串转为数组
4.6 Map和Set
1. Map
Map 是一个带键的数据项的集合,就像一个 Object 一样。 但是它们最大的差别是 Map 允许任何类型的键(key)。
它的方法和属性如下:
new Map()—— 创建 map。map.set(key, value)—— 根据键存储值。map.get(key)—— 根据键来返回值,如果map中不存在对应的key,则返回undefined。map.has(key)—— 如果key存在则返回true,否则返回false。map.delete(key)—— 删除指定键的值。map.clear()—— 清空 map。map.size—— 返回当前元素个数。
Map支持链式调用
2. Map迭代
map.keys()—— 遍历并返回所有的键(returns an iterable for keys),map.values()—— 遍历并返回所有的值(returns an iterable for values),map.entries()—— 遍历并返回所有的实体(returns an iterable for entries)[key, value],for..of在默认情况下使用的就是这个。
和对象不同,map的迭代顺序和插入顺序是一致的
3. Map创建
从数组中创建Map
// 键值对 [key, value] 数组
let map = new Map([
['1', 'str1'],
[1, 'num1'],
[true, 'bool1']
]);
alert( map.get('1') ); // str1从对象中创建Map
let obj = {
name: "John",
age: 30
};
let map = new Map(Object.entries(obj));
alert( map.get('name') ); // John从Map中创建对象
let prices = Object.fromEntries([
['banana', 1],
['orange', 2],
['meat', 4]
]);
// 现在 prices = { banana: 1, orange: 2, meat: 4 }
alert(prices.orange); // 24. Set
new Set(iterable)—— 创建一个set,如果提供了一个iterable对象(通常是数组),将会从数组里面复制值到set中。set.add(value)—— 添加一个值,返回 set 本身set.delete(value)—— 删除值,如果value在这个方法调用的时候存在则返回true,否则返回false。set.has(value)—— 如果value在 set 中,返回true,否则返回false。set.clear()—— 清空 set。set.size—— 返回元素个数。
5. Set迭代
set.keys()—— 遍历并返回所有的值(returns an iterable object for values),set.values()—— 与set.keys()作用相同,这是为了兼容Map,set.entries()—— 遍历并返回所有的实体(returns an iterable object for entries)[value, value],它的存在也是为了兼容Map。
4.7 WeakMap和WeakSet(弱映射和弱集合)
对于普通的Map,存放在里面的对象没有了其它引用也不会被垃圾回收器回收,但是WeakMap则会被回收。
暂不支持访问
WeakMap的所有键/值的方法。
1. 额外的数据存储
例如,我们有用于处理用户访问计数的代码。收集到的信息被存储在 map 中:一个用户对象作为键,其访问次数为值。当一个用户离开时(该用户对象将被垃圾回收机制回收),这时我们就不再需要他的访问次数了。
2. 缓存
当一个函数的结果需要被记住(“缓存”),这样在后续的对同一个对象的调用时,就可以重用这个被缓存的结果。
4.8 解构赋值
1. 数组解构
// 我们有一个存放了名字和姓氏的数组
let arr = ["Ilya", "Kantor"]
// 解构赋值
// sets firstName = arr[0]
// and surname = arr[1]
let [firstName, surname] = arr;
alert(firstName); // Ilya
alert(surname); // Kantor更加优雅的方式
let [firstName, surname] = "Ilya Kantor".split(' ');忽略使用逗号的元素
// 不需要第二个元素
let [firstName, , title] = ["Julius", "Caesar", "Consul", "of the Roman Republic"];
alert( title ); // Consul等号右侧可以是任何可迭代对象
let [a, b, c] = "abc"; // ["a", "b", "c"]
let [one, two, three] = new Set([1, 2, 3]);赋值给等号左侧的任何内容
let user = {};
[user.name, user.surname] = "Ilya Kantor".split(' ');
alert(user.name); // Ilya与 .entries() 方法进行循环操作
let user = {
name: "John",
age: 30
};
// 循环遍历键—值对
for (let [key, value] of Object.entries(user)) {
alert(`${key}:${value}`); // name:John, then age:30
}变量值交换
let guest = "Jane";
let admin = "Pete";
// 交换值:让 guest=Pete, admin=Jane
[guest, admin] = [admin, guest];
alert(`${guest} ${admin}`); // Pete Jane(成功交换!)剩余的”…”
let [name1, name2, ...rest] = ["Julius", "Caesar", "Consul", "of the Roman Republic"];
alert(name1); // Julius
alert(name2); // Caesar
// 请注意,`rest` 的类型是数组
alert(rest[0]); // Consul
alert(rest[1]); // of the Roman Republic
alert(rest.length); // 2默认值
一般情况下变量的数量多余数组中实际元素的数量,被解构的数据就是undefined
// 默认值
let [name = "Guest", surname = "Anonymous", lastName = prompt('name?')] = ["Julius"];
alert(name); // Julius(来自数组的值)
alert(surname); // Anonymous(默认值被使用了)只有当没有被赋值时,才会触发prompt
2. 对象解构
let {prop : varName = default, ...rest} = object使用举例:
let options = {
title: "Menu",
width: 100,
height: 200
};
let {title, width, height} = options;变量顺序并不影响解构结果
如果我们想把一个属性赋值给另一个名字的变量,比如把 options.width 属性赋值给变量 w,那么我们可以使用冒号来指定(原来的会删除):
let options = {
title: "Menu",
width: 100,
height: 200
};
// { sourceProperty: targetVariable }
let {width: w, height: h, title} = options;
// width -> w
// height -> h
// title -> title
alert(title); // Menu
alert(w); // 100
alert(h); // 200对于可能缺失的属性,我们可以像数组解构一样进行指定或者函数调用。
剩余模式(pattern)”…“
let options = {
title: "Menu",
height: 200,
width: 100
};
// title = 名为 title 的属性
// rest = 存有剩余属性的对象
let {title, ...rest} = options;
// 现在 title="Menu", rest={height: 200, width: 100}
alert(rest.height); // 200
alert(rest.width); // 1003. 解构陷阱
let title, width, height;
// 这一行发生了错误
{title, width, height} = {title: "Menu", width: 200, height: 100};这里将不在其他表达式中{...}当作一个代码块,下面给出解决办法:
let title, width, height;
// 现在就可以了
({title, width, height} = {title: "Menu", width: 200, height: 100});
alert( title ); // Menu4. 嵌套解构
let user = {
name: {
first: 'john',
last: 'li'
}
}
let { name } = user;
// 不支持
let {first} = user;
console.log(name.first);4.9 JSON
1. stringify
let json = JSON.stringify(value[, replacer, space])value:被解析对象replacer:传入一个函数function(key, value),用于分析并替换/跳过整个对象space:用于格式化输出,缩进占的空格数。
2. 自定义”toJSON“
对象可以提供toJSON方法,当stringify进行解析时会自动调用该对象
3. parse
let value = JSON.parse(str, [reviver]);str:需要解析的JSON字符串reviver:可选的函数 function(key,value),该函数将为每个(key, value)对调用,并可以对值进行转换。
JSON字符串的属性必须双引号,值必须是裸值不能使用
new关键字
5. 函数进阶
5.1. Rest与Spread
1. Rest参数…
必须是最后一个参数,传入是最后一个参数在函数内部是一个数组
let arr=function(a,b,...args){
console.log(a);
console.log(b);
for (let arg of args) {
console.log(arg);
}
};
arr(1,2,3,4,5,6) // 1 2 3 4 5 62. arguments变量
有一个名为 arguments 的特殊的类数组对象,该对象按参数索引包含所有参数。
let arr=function(){
for (let item of arguments) {
console.log(item);
}
};
arr(1,2,3,4,5,6) // 1 2 3 4 5 6
arguments终究不是一个数组,不能使用数组相关的方法。
箭头函数是没有 “arguments”,如果我们在箭头函数中访问
arguments,访问到的arguments并不属于箭头函数,而是属于箭头函数外部的“普通”函数。
3. Spread语法
将数据解构传入函数
let arr1 = [1, -2, 3, 4];
let arr2 = [8, 3, -8, 1];
alert( Math.max(1, ...arr1, 2, ...arr2, 25) ); // 25
let merged = [0, ...arr, 2, ...arr2];它可以解构任何可迭代对象,比如字符串
4. 获取一个 array/object 的副本
let arr = [1, 2, 3];
let arrCopy = [...arr]; // 将数组 spread 到参数列表中, 然后将结果放到一个新数组
let obj = { a: 1, b: 2, c: 3 };
let objCopy = { ...obj }; // 将对象 spread 到参数列表中, 然后将结果返回到一个新对象5.2. 闭包
1. 嵌套函数
在函数内部仍然可以创建函数,返回值可以返回一个函数。
2. 词法环境
Step1.变量
在 JavaScript 中,每个运行的函数,代码块 {...} 以及整个脚本,都有一个被称为 词法环境(Lexical Environment)的内部(隐藏)的关联对象。
词法环境对象由两部分组成:
环境记录(Environment Record)—— 一个存储所有局部变量作为其属性(包括一些其他信息,例如this的值)的对象。- 对
外部词法环境的引用,与外部代码相关联。
操作函数内部变量实际就是操作该词法环境对象。

Step2.函数声明
与变量的声明类似
Step3.内部和外部的词法环境
当代码要访问一个变量时 —— 首先会搜索内部词法环境,然后搜索外部环境,然后搜索更外部的环境,以此类推,直到全局词法环境。如果在任何地方都找不到这个变量,那么在严格模式下就会报错(在非严格模式下,为了向下兼容,给未定义的变量赋值会创建一个全局变量)。
let makeCount=function(){
let count=0;
return function(){
return ++count;
};
};
let counter=makeCount();
console.log(counter()); // 1
console.log(counter()); // 2闭包 是指内部函数总是可以访问其所在的外部函数中声明的变量和参数,即使在其外部函数被返回(寿命终结)了之后。
JavaScript 中的函数会自动通过隐藏的
[[Environment]]属性记住创建它们的位置,所以它们都可以访问外部变量。
5.3 var
1. 作用域
var的作用域只有函数作用域和全局作用域,没有块级作用域。即var会穿透if,for和其它代码块。
2. IIFE(立即调用函数表达式)
(function() {
var message = "Hello";
alert(message); // Hello
})();
// 下面的括号会导致语法错误
function go() {
}(); // <-- 不能立即调用函数声明
// 其它的创建 IIFE 的方法
(function() {
alert("Parentheses around the function");
})();
(function() {
alert("Parentheses around the whole thing");
}());
!function() {
alert("Bitwise NOT operator starts the expression");
}();
+function() {
alert("Unary plus starts the expression");
}();5.4 全局对象
在浏览器中,使用 var(而不是 let/const!)声明的全局函数和变量会成为全局对象的属性。
var gVar = 5;
alert(window.gVar); // 5(成为了全局对象的属性)5.5 函数对象
函数即对象,我们可以操作对象的方式来处理函数
1. name
使用name来获取函数名
function sayHi() {
alert("Hi");
}
alert(sayHi.name); // sayHi2. length
获取函数参数的个数,但是rest参数不参与计数
3. 自定义属性
可以为函数添加属性,比如计算函数的调用次数
function sayHi() {
alert("Hi");
// 计算调用次数
sayHi.counter++;
}
sayHi.counter = 0; // 初始值
sayHi(); // Hi
sayHi(); // Hi
alert( `Called ${sayHi.counter} times` ); // Called 2 times可以使用函数属性以用来替代闭包
function makeCounter() {
// 不需要这个了
// let count = 0
function counter() {
return counter.count++;
};
counter.count = 0;
return counter;
}
let counter = makeCounter();
alert( counter() ); // 0
alert( counter() ); // 1和闭包的区别就在于一个存储在函数外部,一个存储在函数内部。
4. 命名函数表达式
let sayHi = function func(who) {
if (who) {
alert(`Hello, ${who}`);
} else {
func("Guest"); // 使用 func 再次调用函数自身
sayHi("test");
}
};
sayHi(); // Hello, Guest
// 但这不工作:
func(); // Error, func is not defined(在函数外不可见)关于名字 func 有两个特殊的地方,这就是添加它的原因:
- 它允许函数在内部引用自己。
- 它在函数外是不可见的。
外部将sayHi置空,会导致内部无法调用。
func属于函数作用域,sayHi属于全局作用域
5.6 new Function
let func = new Function ([arg1, arg2, ...argN], functionBody);let sum = new Function('a', 'b', 'return a + b'); // 基础语法
let sum = new Function('a,b', 'return a + b'); // 逗号分隔
let sum = new Function('a , b', 'return a + b'); // 逗号和空格分隔
alert( sum(1, 2) ); // 3使用 new Function 创建函数的应用场景非常特殊,比如在复杂的 Web 应用程序中,我们需要从服务器获取代码或者动态地从模板编译函数时才会使用。
如果我们使用
new Function创建一个函数,那么该函数的[[Environment]]并不指向当前的词法环境,而是指向全局环境。这样做的目的就是在进行压缩代码时,无法找到外部词法环境的变量,因为再次之前它已经被改变了。
5.7 定时函数
1. setTimeout
let timerId = setTimeout(func|code, [delay], [arg1], [arg2], ...)允许我们将函数推迟到一段时间间隔之后再执行。
fun | code:要执行的函数或者代码字符串(不建议)。delay:执行前的延时,以毫秒为单位(1000 毫秒 = 1 秒),默认值是 0。arg:要执行函数的参数列表。
fun参数,主要不要加括号,但是可以使用箭头函数。
嵌套setTimeout
通过嵌套执行 setTimeout 可以完成周期性调度,类似于 setInterval ,并且它可以更加灵活的执行。
两者不同的是:
setTimeout:内部程序间隔时间包含自身函数执行的时间。setInterval:相反内部程序间隔时间不包含自身函数执行时间,而是从函数执行完毕才开始计算时间。
2. clearTimeout
setTimeout 会返回一个 定时器标识符 ,利用此标识可以进行取消 setTimeout。
let timerId = setTimeout(...);
clearTimeout(timerId);3. setInterval
许我们重复运行一个函数,从一段时间间隔之后开始运行,之后以该时间间隔连续重复运行该函数。
let timerId = setInterval(func|code, [delay], [arg1], [arg2], ...)4. clearInterval
和 clearTimeout 类似,它可以取消 setInterval ,方法类似。
当我们以零延时的嵌套定时器或 setInterval 进行循环执行时,它的频率不仅实际不为零,而且在
HTML5标准中所讲:“经过 5 重嵌套定时器之后,时间间隔被强制设定为至少 4 毫秒“。该限制源于远古时代现在的服务端的js都没有这个限制。
5.8 JS的装饰器
由于函数可以作为参数传入另一个函数或者返回一个函数,利用此特性我们可以为函数装饰一个新的功能。
1. 透明缓存
为函数增加缓存功能,函数的调用结果将会被保存,下次调用会优先取缓存,这样做的目的就是避免CPU负载重的任务重复执行。
前提是该函数的结果是稳定的,即传入的内容相同,得出的结果不同。比如某些函数依赖了外部内容比如时间,那么得出的结果可能不同。
function slow(x) {
// 这里可能会有重负载的 CPU 密集型工作
alert(`Called with ${x}`);
return x;
}
// 参数为被装饰的函数。
function cachingDecorator(func) {
// 参数为key,result为value。
let cache = new Map();
return function(x) {
if (cache.has(x)) { // 如果缓存中有对应的结果
return cache.get(x); // 从缓存中读取结果
}
let result = func(x); // 否则就调用 func
cache.set(x, result); // 然后将结果缓存(记住)下来
return result;
};
}
slow = cachingDecorator(slow);
alert( slow(1) ); // slow(1) 被缓存下来了
alert( "Again: " + slow(1) ); // 一样的
alert( slow(2) ); // slow(2) 被缓存下来了
alert( "Again: " + slow(2) ); // 和前面一行结果相同2. func.call
我们为类中的函数做装饰器时,就比如上面的例子,如果在被装饰的函数使用了 this ,那么装饰的结果函数this的指向将会出现问题。
func.call(context, arg1, arg2, ...)context:代表的就是需要包装的函数中使用的this对象
当我们需要传入多个参数时,可以将多个参数生成一个 hash值 ,在将这个值作为map的key。
3. func.apply
func.apply(context, args)该方法和 call 的作用类似,唯一的区别就是apply期望的是包含这些参数的类数组对象。
将所有参数连同上下文一起传递给另一个函数被称为“呼叫转移(call forwarding)
在 hash 函数中,根据参数对象 arguments (非数组)生成的hash值时,由于它不是真正的数组,不可以直接使用数组的方法,但是我们可以使用 方法借用 :
function hash() {
alert( [].join.call(arguments) ); // 1,2
}
hash(1, 2);// TODO
5.9 函数绑定
当我们将对象的方法进行回调进行传递时,通常会丢失它的 this 指向。
1. bind
// 省略版
let boundFunc = func.bind(context);如果绑定的对象在之后被改变了某些内容,但是也会使用预先绑定(pre-bound)的值,该值是对旧的 user 对象的引用。
2. 偏函数(Partial function)
// 完整版
let bound = func.bind(context, [arg1], [arg2], ...);上面的讨论中,我们只是简单的进行绑定 this,在bind中实际上还可以进行参数的绑定。
function mul(a, b) {
return a * b;
}
let double = mul.bind(null, 2);
alert( double(3) ); // = mul(2, 3) = 6它被称为 偏函数应用程序(partial function application) —— 我们通过绑定先有函数的一些参数来创建一个新函数。
通常我们在一个非常通用的函数中,某个参数总是重复的传入,这个时候偏函数非常有用。
6. 对象属性配置
6.1 属性标志
1. 属性标志
writable— 如果为true,则值可以被修改,否则它是只可读的。严格模式下修改会抛出异常。enumerable— 如果为true,则会被在循环中列出,否则不会被列出。configurable— 如果为true,则此特性可以被删除,这些属性也可以被修改,否则不可以。
这些内容通常是被隐藏的,并且值为 true 。
查询某个属性的值及其属性标志值: getOwnPropertyDescriptor
let descriptor = Object.getOwnPropertyDescriptor(obj, propertyName);修改属性:defineProperty
Object.defineProperty(obj, propertyName, descriptor)如果该属性存在,defineProperty 会更新其标志。否则,它会使用给定的值和标志创建属性;在这种情况下,如果没有提供标志,则会假定它是 false。
configurable被设置为false时,我们也不能通过defineProperty在对属性做出修改。
defineProperties 一次性修改多个属性:
Object.defineProperties(user, {
name: { value: "John", writable: false },
surname: { value: "Smith", writable: false },
// ...
});getOwnPropertyDescriptors(obj) 一次性获取多个属性描述符
通常,我们使用循环赋值时进行对象克隆,这种克隆方式通常不会克隆对象的标志。
2. 设定一个全局的密封对象
属性描述符只是限制单个属性,还有一些限制访问整个对象的方法:
-
禁止向对象添加新属性。
-
禁止添加/删除属性。为所有现有的属性设置
configurable: false。 -
禁止添加/删除/更改属性。为所有现有的属性设置
configurable: false, writable: false。
还有针对它们的测试:
-
如果添加属性被禁止,则返回
false,否则返回true。 -
如果添加/删除属性被禁止,并且所有现有的属性都具有
configurable: false则返回true。 -
如果添加/删除/更改属性被禁止,并且所有当前属性都是
configurable: false, writable: false,则返回true。
6.2 getter和setter
let obj = {
get propName() {
// 当读取 obj.propName 时,getter 起作用
},
set propName(value) {
// 当执行 obj.propName = value 操作时,setter 起作用
}
};1. 访问器
所以访问器描述符可能有:
get—— 一个没有参数的函数,在读取属性时工作,set—— 带有一个参数的函数,当属性被设置时调用,enumerable—— 与数据属性的相同,configurable—— 与数据属性的相同。
请注意,一个属性要么是访问器(具有 get/set 方法),要么是数据属性(具有 value),但不能两者都是。
// Error: Invalid property descriptor.
Object.defineProperty({}, 'prop', {
get() {
return 1
},
value: 2
});2. 属性控制
通过getter/setter,我们可以创建一个”属性“,它比原始的属性更加的灵活。
let user = {
get name() {
return this._name;
},
// 限制name的长度
set name(value) {
if (value.length < 4) {
alert("Name is too short, need at least 4 characters");
return;
}
this._name = value;
}
};尽管我们可以通过 _name 访问 name,但是我们约定以下划线开头的属性为内部属性,不应该从对象外部进行访问。
7. 原型,继承
7.1. proto
1. [[Prototype]]
在 JavaScript 中,对象有一个特殊的隐藏属性 [[Prototype]],它要么为 null,要么就是对另一个对象的引用。该对象被称为“原型”。
我们可以通过设置对象的 _proto_ 属性可以完成对象之间的继承:
let animal = {
eats: true
};
let rabbit = {
jumps: true
};
rabbit.__proto__ = animal; // 设置 rabbit.[[Prototype]] = animal当我们读取对象中的某一个属性时,如果找不到它就会顺着 继承链(原型链) 向上寻找。从上面可以观察得到JS的继承是一种单继承。
__proto__是[[Prototype]]的因历史原因而留下来的 getter/setter,__proto__给对象访问原型,.prototype给方法访问原型。
原型继承是包含访问器的继承
2. ”this“指向
无论在哪里找到方法:在一个对象还是在原型中。在一个方法调用中,this 始终是点符号 . 前面的对象。所以,方法是共享的,但对象状态不是。
3. 属性迭代
Object.keys:只返回自己的属性。
for in:会遍历自己以及继承的键。
**obj.hasOwnProperty(key)**:判断该属性是否只属于自己(不包括继承的)。
7.2. F.prototype
曾经我们讲过可以使用构造函数的形式创建一个对象。
let animal = {
eats: true
};
function Rabbit(name) {
this.name = name;
}
Rabbit.prototype = animal;
let rabbit = new Rabbit("White Rabbit"); // rabbit.__proto__ == animal
alert( rabbit.eats ); // true使用这种形式相当于只是为类 Rabbit 创建了一个名为 prototype 的属性,它会在变成对象的那一刻起,该对象的 [[Prototype]] 才被创建。
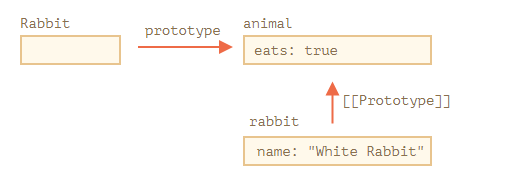
在上图中,"prototype" 是一个水平箭头,表示一个常规属性,[[Prototype]] 是垂直的,表示 rabbit 继承自 animal。
每个函数都有一个默认的F.prototype属性,即使我们从来没有提供过,该属性的指向是一个只有 constructor 属性的对象,而该属性又指向函数本身。

由于constructor指向函数本身,所以也可以使用 constructor 进行对象的创建。
let rabbit2 = new rabbit.constructor("Black Rabbit");JS自身并不能保证
constructor的正确性,我们甚至可以更改该方法。
请注意在
Object.prototype上方的链中没有更多的[[Prototype]]
alert(Object.prototype.__proto__); // null对于基本数据类型,尽管印象中它们不属于对象,但是我们真正创建的时候,它会通过相应的临时包装器的构造器创建,大多数引擎都是对这些进行过优化的。
null和undefined没有对象包装器,没有原型,没有属性方法。
原型可以更改,但是我们十分不建议,因为这会造成一种污染。
只有一种情况下我们允许修改原生原型,那就是 polyfilling 。
Polyfilling 是一个术语,表示某个方法在 JavaScript 规范中已存在,但是特定的 JavaScript 引擎尚不支持该方法,那么我们可以通过手动实现它,并用以填充内建原型。
注意,原型方法中没有 proto 的对象
1. 从原型中进行方法借用
原型方法借用是指,我们从原型中借用一些方法。
let obj = {
0: "Hello",
1: "world!",
length: 2,
};
obj.join = Array.prototype.join;
alert( obj.join(',') ); // Hello,world!上面这段代码有效,是因为内建的方法 join 的内部算法只关心正确的索引和 length 属性。它不会检查这个对象是否是真正的数组。许多内建方法就是这样。
2. 原型其它
__proto__ 被认为是过时且不推荐使用的(deprecated),这里的不推荐使用是指 JavaScript 规范中规定,proto 必须仅在浏览器环境下才能得到支持。
现代的方法有:
- Object.create(proto, descriptors]) —— 利用给定的
proto作为[[Prototype]]和可选的属性描述来创建一个空对象。 - Object.getPrototypeOf(obj) —— 返回对象
obj的[[Prototype]]。 - Object.setPrototypeOf(obj, proto) —— 将对象
obj的[[Prototype]]设置为proto。
通过以上的方法我们可以完成对象的 超级深克隆 ,即克隆对象的属性标志和属性描述符:
let clone = Object.create(Object.getPrototypeOf(obj), Object.getOwnPropertyDescriptors(obj));更改原型将会非常的影响执行速度,更改原型本身是一个非常缓慢的操作,因为它破坏了对象属性访问操作的内部优化。
我们是无法将对象的 _proto_ 的值赋予为字符串
8. 类
8.1. 基本语法
class MyClass {
// class 方法
constructor() { ... }
method1() { ... }
...
}注意类的方法之间没有逗号
在JS中类就是一个函数:
class User {
constructor(name) { this.name = name; }
sayHi() { alert(this.name); }
}
// 佐证:User 是一个函数
alert(typeof User); // function类的原型中才真正存储着类的构造器和定义的方法。所以有人将 class 视为一种定义构造器及其原型方法的语法糖。但是它们之间仍然存在着重大差异:
- 通过
class创建的函数具有特殊的内部属性标记[[IsClassConstructor]]: true,我们输出该类,和普通方法不同的是它会在前面加一个class。 - 类中的方法不可枚举。可以修改对应的属性标志使其可以迭代。
- 类中使用
user strict类的方法里面的所有代码都会自动进入严格模式。
类与函数十分的类似,可以像函数一样在另外一个表达式中被定义,被传递,被返回,被赋值等。
但是一旦类表达式有名字(如上例的User),该名字仅在类内部可见。
let test=class User{}
console.log(test); // 正常输出
console.log(User); // error就像对象字面量,类可能包括 getters/setters,计算属性(computed properties)等。
对于类的字段,只需要使用 ”=“进行设置,和类的方法不同之处在于,它就存在于被创建的对象中,而不是对象的原型中。
正如方法容易丢失 ”this“一样,类也会丢失”this“。
在前面我们讲过一些方法,比如:
- 传递一个包装函数,例如
setTimeout(() => button.click(), 1000)。 - 将方法绑定到对象,例如在 constructor 中。
但是在类中我们可以使用更加优雅的方式:
class Button {
constructor(value) {
this.value = value;
}
click = () => {
alert(this.value);
}
}
let button = new Button("hello");
setTimeout(button.click, 1000); // hello8.2. 类继承(extends)
extends关键字后面不仅仅可以跟类名,还可以跟任意表达式。
function f(phrase) {
return class {
sayHi() { alert(phrase); }
};
}
class User extends f("Hello") {}
new User().sayHi(); // Hello类中使用 super 进行调用父类的方法,同时,箭头函数没有super。
根据规范,如果一个类没有显式的定义 constructor ,那么该方法就会默认的创建
class Rabbit extends Animal {
// 为没有自己的 constructor 的扩展类生成的
constructor(...args) {
super(...args);
}
}和Java类似,在子类中,如果构造函数中使用 this 那么它必须在此之前调用super。
子父类之间从重载不仅可以发生在函数上,还可以发生在字段之中。但是父类的构造器总是使用父类的字段不会使用子类的字段,这是因为在子类初始化完全之前即构造函数调用时,它会首先调用父类的构造方法以完成父类的初始化,所以父类才会调用父类的字段,因为子类还没有完成初始化。
这个与函数是不同的,函数尽管没有完成子类的初始化,但是仍然会进行调用子类的函数。
深入探究Super
// TODO
8.3 静态属性和静态方法
静态属性和静态方法不是存放在类的原型上的而是放在类本身上。这样的属性和方法我们使用static进行修饰。我们可以直接使用”className.method/filed“的操作直接访问或者修改。
class User {
static staticMethod() {
alert(this === User);
}
}
User.staticMethod(); // true静态属性和方法是被继承的。
8.4 私有的和受保护的属性和方法
一个约定俗称的就是在受保护的属性以下划线开始,然后使用getter/setter进行限制,但是这并不是语言级别的强制实施。
如果真正做到私有属性则使用”#“开始作为命名。所以”#name“和”name“完全是两个字段或函数,我们可以在同一个类中进行使用。
8.5 内建类
通过继承的方式进行内建类的扩展,有意思的是有些内建的方法如 filter,map 等 — 返回的对象是通过 constructor 进行构建的而不是直接使用原生的Array,这回有一个很有意思的结果,如果我们创建一个数组的子类,在子类中使用map等函数那么它返回的对象就是子类。
Symbol.species
class PowerArray extends Array {
isEmpty() {
return this.length === 0;
}
// 内建方法将使用这个作为 constructor
static get [Symbol.species]() {
return Array;
}
}内建类没有静态方法继承:
- 当通过extends继承的时候,静态方法和非静态方法都会被继承
- 当没有写extends,默认继承object,此时只有非静态方法会被继承
内建类都是使用的默认继承,所以不继承静态方法。
8.6 类检查
1. instanceof
obj instanceof Class如果 obj 隶属于 Class 类(或 Class 类的衍生类),则返回 true。
使用 Symbol.hasInstance 可以自定义instanceof的判断逻辑。
// 设置 instanceOf 检查
// 并假设具有 canEat 属性的都是 animal
class Animal {
static [Symbol.hasInstance](obj) {
if (obj.canEat) return true;
}
}大多数 class 没有 Symbol.hasInstance。在这种情况下,标准的逻辑是:使用 obj instanceOf Class 检查 Class.prototype 是否等于 obj 的原型链中的原型之一。即逐层比较原型链看是否有相等的类。
与 instanceof 类似的方法是 objA.isPrototypeOf(objB) ,这个方法中如果 objA 处在 objB 的原型链中,则返回 true。
注意在上面的两个方法中,类的构造函数是不会参与比较的,这也就意味着:
function Rabbit() {}
let rabbit = new Rabbit();
// 修改了 prototype
Rabbit.prototype = {};
// ...再也不是 rabbit 了!
alert( rabbit instanceof Rabbit ); // false2. toString
使用Object.prototype.toString来揭示类型
由于部分内建类对Object的toString方法进行重写过,所以我们可以使用 func.call 来进行借用。
console.log(Object.prototype.toString.call([])); // [object Array]3. Symbol.toStringTag
可以使用特殊的对象属性 Symbol.toStringTag 自定义对象的 toString 方法的行为。
let user = {
[Symbol.toStringTag]: "User"
};
alert( {}.toString.call(user) ); // [object User]注意,只能在对象上使用。
8.7 Mixin模式
根据维基百科的定义,mixin 是一个包含可被其他类使用而无需继承的方法的类。
在js中其实现原理就是使用js提供的拷贝方法。
// mixin
let sayHiMixin = {
sayHi() {
alert(`Hello ${this.name}`);
},
};
// 用法:
class User {
constructor(name) {
this.name = name;
}
}
// 拷贝方法
Object.assign(User.prototype, sayHiMixin);
// 现在 User 可以打招呼了
new User("Dude").sayHi(); // Hello Dude!// TODO
9. 错误处理
9.1. try..catch
注意catch中能捕获的错误仅包含运行时error。这类错误被称为“运行时的错误(runtime errors)”,有时被称为“异常(exceptions)”。
try..catch仅能捕获
"计划的(scheduled)”代码中发生异常,如果在异步中或者定时器中出现错误代码将无法捕获。
1. Error对象
当错误发生时,JavaScript 生成一个包含有关其详细信息的对象。然后将该对象作为参数传递给 catch,
Error对象主要有三个属性:
name:Error 名称。例如,对于一个未定义的变量,名称是"ReferenceError"。message:关于 error 的详细文字描述。还有其他非标准的属性在大多数环境中可用。其中被最广泛使用和支持的是:stack:当前的调用栈:用于调试目的的一个字符串,其中包含有关导致 error 的嵌套调用序列的信息。
如果不需要Error对象,那么可以不进行参数传入。
2. Throw
throw 操作符会生成一个 error 对象。理论上任何东西都可以作为一个 Error 对象,甚至是基本数据类型,但最好使用对象,最好使用具有 name 和 message 属性的对象(某种程度上保持与内建 error 的兼容性)。
JavaScript 中有很多内建的标准 error 的构造器:Error,SyntaxError,ReferenceError,TypeError 等。我们也可以使用它们来创建 error 对象。
3. 再次抛出
由于在try中发生的所有错误,我们都会被catch接收到,但是接受到的这个错误可能会含有一些我们意料之外的错误,这个时候我们通过 instanceof 进行判断,如果不是意料之中的错误,那么就进行再次抛出,即在catch 中重复使用 throw。
function readData() {
let json = '{ "age": 30 }';
try {
// ...
blabla(); // error!
} catch (e) {
// ...
if (!(e instanceof SyntaxError)) {
throw e; // 再次抛出(不知道如何处理它)
}
}
}
try {
readData();
} catch (e) {
alert( "External catch got: " + e ); // 捕获了它!
}3. finally
finally里面的代码无论是否错误都是会被执行的。
注意 try catch finally三个代码块中的代码的作用域是相互隔离的
catch 和 finally 两者只能省略一个
正如人生一样,我们总是无法去预测所有意外,如果仅仅因为某一个未知的意外从而导致整个程序的死亡,那是不是未免太过于不值得了。
尽管规范中没有相关内容,但是代码的执行环境一般会提供这种机制,因为它确实很有用。但是在某些运行环境中会提供相关方法来进行捕获那些未知的意外,在浏览器中,我们可以将将一个函数赋值给特殊的 window.onerror 属性,该函数将在发生未捕获的 error 时执行。
window.onerror = function(message, url, line, col, error) {
// ...
};message:Error信息url:发生 error 的脚本的 URL。`line`,`col`:发生 error 处的代码的行号和列号。`error`:Error 对象。
全局错误处理程序 window.onerror 的作用通常不是恢复脚本的执行 — 如果发生编程错误,那这几乎是不可能的(因为拿着个错误的结果继续执行也没有意义),它的作用是将错误信息发送给开发者。
9.2 Error扩展
通过对内建类的继承以完成Error扩展
class ValidationError extends Error {
constructor(message) {
super(message);
this.name = this.constructor.name; // ValidationError
}
}我们在使用时也应该像再次抛出中一样,多次判断并最终抛出到外层。
包装异常
当我们的异常量增加的时候,如果每个都需要用if进行判断那是否未免有点过于麻烦了。
我们可以在抛出时处理,即无论什么异常统一进行二次抛出,并抛出同一个异常。这样进行接受时只需要进行处理一次。
10 Promise, async/await
10.1 回调
所谓回调就是当函数执行完毕之后会进行执行另一段代码,我们通常的做法是,将回调函数作为参数传入给函数,再在函数最后一句执行传入的函数:
function callback(back){
// ... 执行任务
// ... 执行完毕
back()
}
callback(function(){
console.log('test');
}); // test如果我们需要等第一个执行完,再执行第二个,第二个执行完再执行第三个….,我们就需要在回调中继续回调…,这就造成了 厄运金字塔(回调地狱),即内部不断的嵌套。

但是我们可以各个函数都设计成顶层函数:
function test(){
step1();
step2();
step3();
...
}但是这很不方便,特别是如果读者对代码不熟悉,他们甚至不知道应该跳转到什么地方。
此外,名为 step* 的函数都是一次性使用的,创建它们就是为了避免“厄运金字塔”。没有人会在行为链之外重用它们。因此,这里的命名空间有点混乱。
1. Promise
Promise 对象的构造器(constructor)语法如下:
let promise = new Promise(function(resolve, reject) {
// executor(生产者代码,“歌手”)
});传递给Promise的函数被称为 executor。
它的参数 resolve 和 reject 是由 JavaScript 自身提供的回调。我们的代码仅在 executor 的内部。
resolve(value)— 如果任务成功完成并带有结果value。reject(error)— 如果出现了 error,error即为 error 对象,可以不传入error对象,但是建议不这样。
由 new Promise 构造器返回的 promise 对象具有以下内部属性:
state— 最初是"pending",然后在resolve被调用时变为"fulfilled",或者在reject被调用时变为"rejected"。result— 最初是undefined,然后在resolve(value)被调用时变为value,或者在reject(error)被调用时变为error。
executor,只能调用一个函数,如果首先调用了resolve,接下来又调用reject,那么reject将会被忽略。
2. then, catch, finally
1. then
.then接受两个函数作为参数,即当promise得到结果后,第一个参数为成功的回调函数,第二个参数为失败的回调函数。如果我们只对成功的结果感兴趣,那么可以只传入成功的回调函数。
2. catch
如果我们只对失败的结果感兴趣,那么可以在 then 中,第一参数为null,第二个为失败的回调函数。这样有点别扭,于是我们提供了 .catch,这两者的结果都是相同的,相当于只是 then的简写形式。
3. finally
即promise无论成功还是失败都会被执行的代码。在finally后我们可以将程序结果传递给下一个处理程序。
new Promise((resolve, reject) => {
/* 做一些需要时间的事儿,然后调用 resolve/reject */
})
// 在 promise 为 settled 时运行,无论成功与否
.finally(() => stop loading indicator)
// 所以,加载指示器(loading indicator)始终会在我们处理结果/错误之前停止
.then(result => show result, err => show error)10.2 Promise 链
promise的结果是在then中接受,但是then或者其它函数返回的结果都仍然是一个promise,then传入的两个函数中返回的结果可以被下一个then所接受,这样一层一层的传递就形成了一个 promise链 。
new Promise(function (resove, reject) {
resove('ok')
}).then(r=> (r+' fine')).then(r=>console.log(r)) //ok fine如果在then中返回的是新的promise,那么then函数的结果就是那个新的promise。
确切地说,处理程序(handler)返回的不完全是一个 promise,而是返回的被称为 “thenable” 对象 。这个 “thenable”对象具有then方法,所以会被当作一个promise处理。在这个自定义的then方法有点类似创建promise传入的executor。
10.3 Promise错误处理
在Promise链中可以调用多次then,建议将catch放到最后,这样无论前面的哪一个then出错,它都会在最后的catch进行统一处理。
无论是Promise中reject还是编码中的异常,那么这些所有的异常都可以被catch所捕获,这就相当于promise周围被隐式地使用try catch。同理我们可以在catch中进行二次抛出。并且可以使用promise链的下一个then进行处理。
如果promise中进行了reject,并且函数没有catch处理,那么JS引擎将会生成一个全局的error。
由于promise异步执行的特点,如果我们进行捕获错误的时间在promise错误发生之前,即为捕获到,那么promise将会错误。
10.4 Promise API
1. Promise.all
let promise = Promise.all([...promises...]);请注意,结果数组中元素的顺序与其在源 promise 中的顺序相同。即使第一个 promise 花费了最长的时间才 resolve,但它仍是结果数组中的第一个。
一个常见的技巧就是,使用map函数生成promise数组以进行最终处理:
let names = ['iliakan', 'remy', 'jeresig'];
let requests = names.map(name => fetch(`https://api.github.com/users/${name}`));
Promise.all(requests)
.then(responses => {
// 所有响应都被成功 resolved
for(let response of responses) {
alert(`${response.url}: ${response.status}`); // 对应每个 url 都显示 200
}
return responses;
})
// 将响应数组映射(map)到 response.json() 数组中以读取它们的内容
.then(responses => Promise.all(responses.map(r => r.json())))
// 所有 JSON 结果都被解析:"users" 是它们的数组
.then(users => users.forEach(user => alert(user.name)));如果当中的任意一个promise出现了reject,那么被 reject 的 error 成为了整个 Promise.all 的结果,其它的promise将会被忽略。
通常,
Promise.all(...)接受含有 promise 项的可迭代对象(大多数情况下是数组)作为参数。但是,如果这些对象中的任何一个不是 promise,那么它将被“按原样”传递给结果数组。
2. Promise.allSettled
Promise.allSettled 等待所有的 promise 都被 settle,无论结果如何。结果数组具有:
{status:"fulfilled", value:result}对于成功的响应,{status:"rejected", reason:error}对于 error。
Promise.allSettled如果不支持,那么创建它的pilyfill
if (!Promise.allSettled) {
const rejectHandler = reason => ({ status: 'rejected', reason });
const resolveHandler = value => ({ status: 'fulfilled', value });
Promise.allSettled = function (promises) {
const convertedPromises = promises.map(p => Promise.resolve(p).then(resolveHandler, rejectHandler));
return Promise.all(convertedPromises);
};
}3. Promise.race
等待第一个Promise结果为正常的,就算第一个promise是reject也会忽略。
4. Promise.resolve/reject
在现代的代码中,很少需要使用 Promise.resolve 和 Promise.reject 方法,因为 async/await 语法(我们会在 稍后 讲到)使它们变得有些过时了。
Promise.resolve(value) 用结果 value 创建一个 resolved 的 promise。
// 和这个结果类似
let promise = new Promise(resolve => resolve(value));Promise.reject(error) 用 error 创建一个 rejected 的 promise。
// 和这个结果类似
let promise = new Promise((resolve, reject) => reject(error));10.5 Promisification
“Promisification” 是用于一个简单转换的一个长单词。它指将一个接受回调的函数转换为一个返回 promise 的函数。
function promisify(f) {
return function (...args) { // 返回一个包装函数(wrapper-function) (*)
return new Promise((resolve, reject) => {
function callback(err, result) { // 我们对 f 的自定义的回调 (**)
if (err) {
reject(err);
} else {
resolve(result);
}
}
args.push(callback); // 将我们的自定义的回调附加到 f 参数(arguments)的末尾
f.call(this, ...args); // 调用原始的函数
});
};
}
// 用法:
let loadScriptPromise = promisify(loadScript);
// loadScriptPromise(...).then(...);也有一些具有更灵活一点的 promisification 函数的模块(module),例如 es6-promisify。在 Node.js 中,有一个内建的 promisify 函数 util.promisify。
Promise 处理始终是异步的,因为所有 promise 行为都会通过内部的 “promise jobs” 队列,也被称为“微任务队列”(ES8 术语)。
如果我们需要将代码执行进行放在proimse结果之后执行,可以将代码放在then中。
10.6 Async/Await
1. Async function
在函数前面的 “async” 这个单词表达了一个简单的事情:即这个函数总是返回一个 promise。其他值将自动被包装在一个 resolved 的 promise 中。
2. Await
关键字 await 让 JavaScript 引擎等待直到 promise 完成(settle)并返回结果,他只在 async 函数内部使用。
await 实际上会暂停函数的执行,直到 promise 状态变为 settled,然后以 promise 的结果继续执行。这个行为不会耗费任何 CPU 资源,因为 JavaScript 引擎可以同时处理其他任务:执行其他脚本,处理事件等。
相比于 promise.then,它只是获取 promise 的结果的一个更优雅的语法,同时也更易于读写。
await 不能在顶层使用,这是因为await旨在async函数内部使用,但是从 V8 引擎 8.9+ 版本开始,顶层 await 可以在 模块 中工作。
像 promise.then 那样,await 允许我们使用 thenable 对象(那些具有可调用的 then 方法的对象)。
如果await等待的结果是一个 error,那么可以使用try catch来接受错误,如果没有处理那么包含await的async函数返回的promise将会包含这个错误。
async/await 可以和 Promise.all 一起使用
let results = await Promise.all([
fetch(url1),
fetch(url2),
...
]);如果出现 error,也会正常传递,从失败了的 promise 传到 Promise.all,然后变成我们能通过使用 try..catch 在调用周围捕获到的异常(exception)。
11. Generator, 高级 iteration
11.1 Generator
常规函数只会返回一个单一值(或者不返回任何值)。
而 Generator 可以按需一个接一个地返回(“yield”)多个值。它们可与 iterable 完美配合使用,从而可以轻松地创建数据流。
1. Generator函数
function* generateSequence() {
yield 1;
yield 2;
return 3;
}Generator 函数与常规函数的行为不同。在此类函数被调用时,它不会运行其代码。而是返回一个被称为 “generator object” 的特殊对象,来管理执行流程。
generator 对象当中最重要的方法就是 next(),next执行后会运行到最近的yield为止并返回后面的的数据(像return一样 可返回空[undefined]),return并不是必须的。next的结果始终是一个具有两个属性的对象:
value: 产出的(yielded)的值。done: 如果 generator 函数已执行完成则为true,否则为false。
如果执行完之后再进行next那么返回的结果将没有意义,都是一样的对象:{done: true}。
function* f(…)或function *f(…)都可以
2. 迭代Generator
这是因为 Generator 对象含有 next 方法。可以使用for of的方式进行迭代,但是 return返回的结果并不会迭代出来,可以将return换成yeild。
正是因为 Generator 的可迭代性,所以我们可以使用解构符将结果直接解构出来
可以使用Generator函数去创建迭代器
let range = {
from: 1,
to: 5,
*[Symbol.iterator]() { // [Symbol.iterator]: function*() 的简写形式
for(let value = this.from; value <= this.to; value++) {
yield value;
}
}
};
alert( [...range] ); // 1,2,3,4,5迭代器期望得到的对象正是 Generator 所生成的。
Generator 可以永远进行产出(yield),比如我们生成一个无序的随机数序列。
3. Generator组合
Generator 组合(composition)是 generator 的一个特殊功能,它允许透明地(transparently)将 generator 彼此“嵌入(embed)”到一起。
yield* 指令将执行 委托 给另一个 generator。
4. 双向的“yield”
事实上,yield可以接受到来自外界的参数(不是在Generator函数中)。
function* gen() {
let ask1 = yield "2 + 2 = ?";
alert(ask1); // 4
let ask2 = yield "3 * 3 = ?"
alert(ask2); // 9
}
let generator = gen();
// 如果在这里传入参数将会被忽略
alert( generator.next().value ); // "2 + 2 = ?"
alert( generator.next(4).value ); // "3 * 3 = ?"
alert( generator.next(9).done ); // true既然yield可以传入内容进入那么它也可以在那里发起(抛出)一个 error。这很自然,因为 error 本身也是一种结果。
generator.throw(new Error("Test Error"))如果在 Generator 函数中使用try catch在相应的yield,那么可以接收到这个错误。
如果我们没有在那里捕获这个 error,那么,通常,它会掉入外部调用代码(如果有),如果在外部也没有被捕获,则会杀死脚本。
11.2 异步迭代和Generator
1. 异步迭代
当我们从网络中进行分片下载数据时,异步迭代来进行实现可能会更加方便。
要使对象异步迭代:
使用
Symbol.asyncIterator取代Symbol.iterator。next() 方法应该返回一个 promise(带有下一个值,并且状态为fulfilled)
- 关键字
async可以实现这一点,我们可以简单地使用async next()。
- 关键字
我们应该使用
for await (let item of iterable)循环来迭代这样的对象。- 注意关键字
await。
- 注意关键字
事实上,我们可以在对象中即可以异步迭代也可以同步迭代,只是这很奇怪罢了。
异步迭代无法使用解构符。
2. 异步generator
和异步迭代类似,只需要在函数前面加一个async,使用时使用异步迭代的使用方式。
12. 模块(Module)
12.1. 模块简介
一个模块(module)就是一个文件。一个脚本就是一个模块。
export关键字标记了可以从当前模块外部访问的变量和函数。import关键字允许从其他模块导入功能。
如果在HTML的Script标签中使用模块则需要告诉浏览器:
<script type="module">
import {sayHi} from './say.js';
document.body.innerHTML = sayHi('John');
</script>模块只通过 HTTP(s) 工作,在本地文件则不行。本地文件若想使用可以用Serve开启服务器。
模块始终使用
“user strict”
模块的作用域只有在自己的文件中才会有效
模块代码仅在第一次导入时被解析,被暴露的对象,在所有的导入中都只是一个,任意一个修改都会触发其它的修改
模块的顶级
this是undefined
模块加载总是
延迟的
具有
type = "module"属性相同的外部脚本<script>只会被执行一次
import引入时必须包含绝对路径或者相对路径,没有路径的模块被称为裸模块,这是不被允许的
1. import.meta
import.meta 对象包含关于当前模块的信息。
它的内容取决于其所在的环境。在浏览器环境中,它包含当前脚本的 URL,或者如果它是在 HTML 中的话,则包含当前页面的 URL。
2. 兼容性
早期的浏览器并不支持moudle,我们可以准备一个nomodule来用作不支持的情况。
<script type="module">
alert("Runs in modern browsers");
</script>
<script nomodule>
alert("Modern browsers know both type=module and nomodule, so skip this")
alert("Old browsers ignore script with unknown type=module, but execute this.");
</script>3. 构建工具
它会帮助我们分析它的依赖,优化导入,处理过程中,删除无法访问的代码、未使用的导入等等,并且转换后它并不包含import或者export,这意味着它可以运行在不支持moudle的浏览器中。
12.2. 导入和导出
1. 声明前导出
我们可以通过在声明之前放置 export 来标记任意声明为导出,无论声明的是变量,函数还是类都可以。
注意,导出的class和function末尾是没有分号的,这是因为export不会将其变成函数表达式,尽管被导出了,他仍然是一个函数声明。
2. 分开导出
// 📁 say.js
function sayHi(user) {
alert(`Hello, ${user}!`);
}
function sayBye(user) {
alert(`Bye, ${user}!`);
}
export {sayHi, sayBye}; // 导出变量列表3. import
import {sayHi, sayBye} from './say.js';我们可以使用 import * as <obj> 将所有内容导入为一个对象
import * as say from './say.js';
say.sayHi('John');
say.sayBye('John');不建议全部导出,这是因为在现代的构建工具中,它会根据导出进行优化,将那些未被导出的内容进行删除从而减少代码体量。
4. import as
为导入的内容取别名
import {sayHi as hi, sayBye as bye} from './say.js';
hi('John'); // Hello, John!
bye('John'); // Bye, John!5. export as
为导出的内容取别名
export {sayHi as hi, sayBye as bye};6. export default
每个js文件中只会有一个默认导出,默认导出在使用时(导入时)不需要使用花括号
| 命名的导出 | 默认的导出 |
|---|---|
export class User {...} |
export default class User {...} |
import {User} from ... |
import User from ... |
被默认导出的内容可以不需要命名
另一种默认导出方式:
function sayHi(user) {
alert(`Hello, ${user}!`);
}
// 就像我们在函数之前添加了 "export default" 一样
export {sayHi as default};
// 为默认导出命名
import {default as User, sayHi} from './user.js';
new User('John');如果我们将所有东西 * 作为一个对象导入,那么 default 属性正是默认的导出:
// 📁 main.js
import * as user from './user.js';
let User = user.default; // 默认的导出
new User('John');使用默认导出时,在团队工作中每个人为导入的命名可能都不一样,所以我们定下规则,导入的变量应该和文件名对应
7. 重新导出
“重新导出(Re-export)”语法 export ... from ... 允许导入内容,并立即将其导出(可能是用的是其他的名字)
什么时候使用它嘞?当我们编写package可能内部包含了许多的moudle,这些module可能会引用,这就需要进行导入导出,但是这些module我们又不希望被其它使用这个package的用户所导入,我们希望用户只能够导入我们规定为用户导出的内容,这就需要重新导出。
我们可以单独创建一个文件用来单独的重新导出我们规定的文件。
8. 重新导出默认导出
普通的重新导出语法在进行重新导出时是无效的会有语法错误,进行全部重新导出时把并不会导出默认导出。
我们必须明确写出 export {default as User} from './user.js';
12.3. 动态导入
import()表达式
import(module) 表达式加载模块并返回一个 promise,该 promise resolve 为一个包含其所有导出的模块对象。我们可以在代码中的任意位置调用这个表达式。
注意import并不是一个函数,尽管看起来像,但是我们不能像变量一样对其进行赋值,只是它的语法结构恰好和函数类似
13. 杂项
13.1 Proxy和Reflect
1. Proxy
let proxy = new Proxy(target, handler)target—— 是要包装的对象,可以是任何东西,包括函数。handler—— 代理配置:带有“捕捉器”(“traps”,即拦截操作的方法)的对象。比如get捕捉器用于读取target的属性,set捕捉器用于写入target的属性,等等。
Proxy 是一种特殊的“奇异对象(exotic object)”。它没有自己的属性。如果 handler 为空,则透明地将操作转发给 target。
let target = {};
let proxy = new Proxy(target, {}); // 空的 handler 对象
proxy.test = 5; // 写入 proxy 对象 (1)
alert(target.test); // 5,test 属性出现在了 target 中!
alert(proxy.test); // 5,我们也可以从 proxy 对象读取它 (2)对于对象的大多数操作,JavaScript 规范中有一个所谓的“内部方法”,它描述了最底层的工作方式。Proxy 捕捉器会拦截这些方法的调用。
| 内部方法 | Handler 方法 | 何时触发 |
|---|---|---|
[[Get]] |
get |
读取属性 |
[[Set]] |
set |
写入属性 |
[[HasProperty]] |
has |
in 操作符 |
[[Delete]] |
deleteProperty |
delete 操作符 |
[[Call]] |
apply |
函数调用 |
[[Construct]] |
construct |
new 操作符 |
[[GetPrototypeOf]] |
getPrototypeOf |
Object.getPrototypeOf |
[[SetPrototypeOf]] |
setPrototypeOf |
Object.setPrototypeOf |
[[IsExtensible]] |
isExtensible |
Object.isExtensible |
[[PreventExtensions]] |
preventExtensions |
Object.preventExtensions |
[[DefineOwnProperty]] |
defineProperty |
Object.defineProperty, Object.defineProperties |
[[GetOwnProperty]] |
getOwnPropertyDescriptor |
Object.getOwnPropertyDescriptor, for..in, Object.keys/values/entries |
[[OwnPropertyKeys]] |
ownKeys |
Object.getOwnPropertyNames, Object.getOwnPropertySymbols, for..in, Object/keys/values/entries |
不变量:JavaScript 强制执行某些不变量 — 内部方法和捕捉器必须满足的条件。
2. Get使用
get(target, property, receiver)
target—— 是目标对象,该对象被作为第一个参数传递给new Proxy,property—— 目标属性名,receiver—— 如果目标属性是一个 getter 访问器属性,则receiver就是本次读取属性所在的this对象。通常,这就是proxy对象本身(或者,如果我们从 proxy 继承,则是从该 proxy 继承的对象)。现在我们不需要此参数,因此稍后我们将对其进行详细介绍。
let numbers = [0, 1, 2];
numbers = new Proxy(numbers, {
get(target, prop) {
if (prop in target) {
return target[prop];
} else {
return 0; // 默认值
}
}
});
alert( numbers[1] ); // 1
alert( numbers[123] ); // 0(没有这个数组项)注意当对象被代理后,代理应该在所有地方都完全替代目标对象。目标对象被代理后,任何人都不应该再引用目标对象。否则很容易搞砸。
3. Set
set(target, property, value, receiver):
target—— 是目标对象,该对象被作为第一个参数传递给new Proxy,property—— 目标属性名称,value—— 目标属性的值,receiver—— 与get捕捉器类似,仅与 setter 访问器属性相关。
let numbers = [];
numbers = new Proxy(numbers, { // (*)
set(target, prop, val) { // 拦截写入属性操作
if (typeof val == 'number') {
target[prop] = val;
return true;
} else {
return false;
}
}
});
numbers.push(1); // 添加成功
numbers.push("test"); // TypeError(proxy 的 'set' 返回 false)请注意:数组的内建方法依然有效!值被使用
push方法添加到数组。当值被添加到数组后,数组的length属性会自动增加。我们的代理对象 proxy 不会破坏任何东西。
// TODO
13.2 Eval:执行代码字符串
内建函数 eval 允许执行一个代码字符串。
let code = 'alert("Hello")';
eval(code); // Helloeval 内的代码在当前词法环境(lexical environment)中执行,因此它能访问外部变量,同时也可以修改。
在严格模式下,eval有自己的词法环境,不能在外界获取它的函数和变量。
请注意,eval 访问外部变量的能力会产生副作用。在代码压缩工具中,由于eval中的变量无法访问,这回造成压缩效率的降低,因此在 eval 中使用外部局部变量也被认为是一个坏的编程习惯,因为这会使代码维护变得更加困难。
如果 eval 中的代码没有使用外部变量,请以 window.eval(…) 的形式调用 eval,eval中的环境就变成了window
13.3 柯里化
柯里化是一种函数的转换,它是指将一个函数从可调用的 f(a, b, c) 转换为可调用的 f(a)(b)(c)。
柯里化更高级的实现,例如 lodash 库的 _.curry,会返回一个包装器,该包装器允许函数被正常调用或者以偏函数(partial)的方式调用
高级柯里化
function curry(func) {
return function curried(...args) {
// 和函数本身的应该的参数列表进行比较
if (args.length >= func.length) {
return func.apply(this, args);
} else {
return function(...args2) {
// 如果小于的话就保存到当前的词法环境中,并与当前词法环境已经含有的参数进行拼接
return curried.apply(this, args.concat(args2));
}
}
};
}柯里化要求函数的参数必须是固定的,换句话说含有 rest 参数的函数无法进行柯里化。
13.4 Reference Type
实际上,当我执行对象中的一个函数时 user.sayHi() “.”后sayHi返回的并不是一个sayHi函数,而是一个 Reference Type 值。
Reference Type 的值是一个三个值的组合 (base, name, strict),其中:
base是对象。name是属性名。strict在use strict模式下为 true。
// Reference Type 的值
(user, "sayHi", true)任何例如赋值 hi = user.sayHi 等其他的操作,都会将 Reference Type 作为一个整体丢弃掉,而会取 user.sayHi(一个函数)的值并继续传递。所以任何后续操作都“丢失”了 this。(使用 [] 取作用类似)
2. 浏览器:文档、事件、接口

1. Document
1.1 简介
1. DOM
文档对象模型(Document Object Model),简称 DOM,将所有页面内容表示为可以修改的对象。
2. CSSOM
一份针对 CSS 规则和样式表的、单独的规范 CSS Object Model (CSSOM),这份规范解释了如何将 CSS 表示为对象,以及如何读写这些对象。
当我们修改文档的样式规则时,CSSOM 与 DOM 是一起使用的。但实际上,很少需要 CSSOM,因为我们很少需要从 JavaScript 中修改 CSS 规则(我们通常只是添加/移除一些 CSS 类,而不是直接修改其中的 CSS 规则),但这也是可行的。
3. BOM
浏览器对象模型(Browser Object Model),简称 BOM,表示由浏览器(主机环境)提供的用于处理文档(document)之外的所有内容的其他对象。
1.2 DOM树
HTML 文档的主干是标签(tag)。
根据文档对象模型(DOM),每个 HTML 标签都是一个对象。嵌套的标签是闭合标签的“子标签(children)”。标签内的文本也是一个对象。
标签被称为 元素节点(或者仅仅是元素),并形成了树状结构:<html> 在根节点,<head> 和 <body> 是其子项,等。
元素内的文本形成 文本节点,被标记为 #text。一个文本节点只包含一个字符串。它没有子项,并且总是树的叶子。
注释也会成为一个节点,被标记为 #comment。
HTML 中的所有内容,甚至注释,都会成为 DOM 的一部分。
标签中空格和换行符都是完全有效的字符,它们形成文本节点并成为 DOM 的一部分。
只有两个顶级排除项:
- 由于历史原因,
<head>之前的空格和换行符均被忽略。 - 如果我们在
</body>之后放置一些东西,那么它会被自动移动到body内,并处于body中的最下方,因为 HTML 规范要求所有内容必须位于<body>内。所以</body>之后不能有空格。
一共有 12 种节点类型。实际上,我们通常用到的是其中的 4 种:
document— DOM 的“入口点”。- 元素节点 — HTML 标签,树构建块。
- 文本节点 — 包含文本。
- 注释 — 有时我们可以将一些信息放入其中,它不会显示,但 JS 可以从 DOM 中读取它。
自动修正
如果浏览器遇到格式不正确的 HTML,它会在形成 DOM 时自动更正它。
例如 html 和 body 标签,即使它不存在于文档中,也会被自动创建。
未闭合的标签会进行自动闭合。
表格永远有<tbody>
1.3 DOM遍历
1. 顶层节点
<html>=document.documentElement
最顶层的 document 节点是 document.documentElement。这是对应 <html> 标签的 DOM 节点。
<body>=document.body`
另一个被广泛使用的 DOM 节点是 <body> 元素 — document.body。
<head>=document.head
<head> 标签可以通过 document.head 访问。
如果在body渲染前进行读body对象(代码在head中),那么返回的为空。
2. 子节点
- 子节点(或者叫作子) — 对应的是直系的子元素。换句话说,它们被完全嵌套在给定的元素中。例如,
<head>和<body>就是<html>元素的子元素。 - 子孙元素 — 嵌套在给定元素中的所有元素,包括子元素,以及子元素的子元素等。
firstChild 和 lastChild 属性是访问第一个和最后一个子元素的快捷方式。
这里还有一个特别的函数 elem.hasChildNodes() 用于检查节点是否有子节点。
正如我们看到的那样,childNodes 看起来就像一个数组。但实际上它并不是一个数组,而是一个 集合 — 一个类数组的可迭代对象。
反应在该性质上就是:
- 可以使用 for of 进行迭代
- 无法使用数组相关的方法
DOM 集合是只读的
无法通过更改集合来反向应该DOM
DOM 集合是实时的
如果在其他地方更改DOM,那么DOM集合也会实时更新
不要使用 for..in 来遍历集合
for..in 循环遍历的是所有可枚举的(enumerable)属性。集合还有一些“额外的”很少被用到的属性,通常这些属性也是我们不期望得到的。
3. 兄弟节点和父节点
下一个兄弟节点在 nextSibling 属性中,上一个是在 previousSibling 属性中。
可以通过 parentNode 来访问父节点。
4. 纯元素导航
在上面的访问方式中,我们可以访问到元素的所有节点,但是有时候我们不需要访问它的文本节点或者注释节点。我们希望操纵的是代表标签的和形成页面结构的元素节点。
这些链接和我们在上面提到过的类似,只是在词中间加了 Element:
children— 仅那些作为元素节点的子代的节点。firstElementChild,lastElementChild— 第一个和最后一个子元素。previousElementSibling,nextElementSibling— 兄弟元素。parentElement— 父元素。
parentElement 访问父元素,parentNode访问父节点,弹道父节点和父元素可以不是同一个元素吗?它在几乎所有的情况下都满足,除了一个例外:
alert( document.documentElement.parentNode ); // document
alert( document.documentElement.parentElement ); // null原因就是 document不是一个元素节点。
5. 其它特殊属性
方便起见,某些类型的 DOM 元素可能会提供特定于其类型的其他属性。
表格(Table)是一个很好的例子,它代表了一个特别重要的情况:
<table> 元素支持 (除了上面给出的,之外) 以下这些属性:
- table.rows — <tr> 元素的集合。
- table.caption/tHead/tFoot — 引用元素 <caption>,<thead>,<tfoot>。
- table.tBodies — <tbody> 元素的集合(根据标准还有很多元素,但是这里至少会有一个 — 即使没有被写在 HTML 源文件中,浏览器也会将其放入 DOM 中)。
<thead>,<tfoot>,<tbody> 元素提供了 rows 属性:
tbody.rows— 表格内部<tr>元素的集合。
<tr>:
tr.cells— 在给定<tr>中的<td>和<th>单元格的集合。tr.sectionRowIndex— 给定的<tr>在封闭的<thead>/<tbody>/<tfoot>中的位置(索引)。tr.rowIndex— 在整个表格中<tr>的编号(包括表格的所有行)。
<td> 和 <th>:
td.cellIndex— 在封闭的<tr>中单元格的编号。
1.4 元素节点搜索
1. document.getElementById 或者只使用 id
<div id="elem">
<div id="elem-content">Element</div>
</div>
<script>
// 第一种方式
// elem 是对带有 id="elem" 的 DOM 元素的引用
elem.style.background = 'red';
// id="elem-content" 内有连字符,所以它不能成为一个变量
// ...但是我们可以通过使用方括号 window['elem-content'] 来访问它
// 第二种方式
// 获取该元素,这种方式优先级高,会覆盖第一种
let elem = document.getElementById('elem');
// 将该元素背景改为红色
elem.style.background = 'red';
</script>第一种方式只是为了兼容性才使用它,除非特殊情况,那么不建议使用它,容易造成冲突。
2. querySelectorAll
到目前为止,最通用的方法是 elem.querySelectorAll(css),它返回 elem 中与给定 CSS 选择器匹配的所有元素。
3. querySelector
elem.querySelector(css) 调用会返回给定 CSS 选择器的第一个元素。
换句话说,结果与 elem.querySelectorAll(css)[0] 相同,但是后者会查找 所有 元素,并从中选取一个,而 elem.querySelector 只会查找一个。因此它在速度上更快,并且写起来更短。
4. matches
elem.matches(css) 不会查找任何内容,它只会检查 elem 是否与给定的 CSS 选择器匹配。它返回 true 或 false。
5. closest
elem.closest(css) 方法会查找与 CSS 选择器匹配的最近的祖先。elem 自己也会被搜索。
6. getElementsBy*
elem.getElementsByTagName(tag)查找具有给定标签的元素,并返回它们的集合。tag参数也可以是对于“任何标签”的星号"*"。elem.getElementsByClassName(className)返回具有给定CSS类的元素。document.getElementsByName(name)返回在文档范围内具有给定name特性的元素。很少使用。
这些方法已经成为了历史,因为 querySelector 过于强大,且写起来更短。
注意上面的方法返回的是一个集合而不是一个元素。这在使用时需要小心。
所有的 "getElementsBy*" 方法都会返回一个 实时的(live) 集合。
相反,querySelectorAll 返回的是一个 静态的 集合。
1.5 节点属性
1. DOM节点类
每个DOM节点都有一个与之对应的内建类,类中的属性和方法既有共同的,也有不同的。
层次结构(hierarchy)的根节点是 EventTarget,Node 继承自它,其他 DOM 节点继承自 Node。
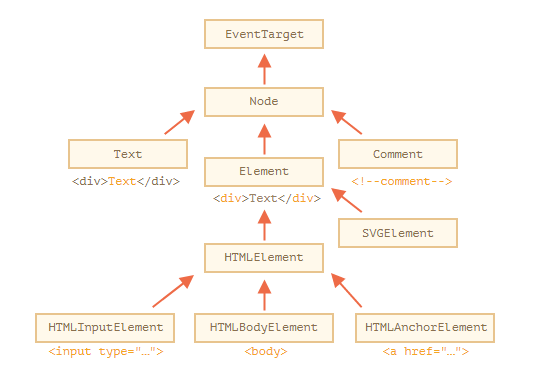
nodeType 属性
nodeType 属性提供了另一种“过时的”用来获取 DOM 节点类型的方法。
它有一个数值型值(numeric value):
- 对于元素节点
elem.nodeType == 1, - 对于文本节点
elem.nodeType == 3, - 对于 document 对象
elem.nodeType == 9, - 在 规范 中还有一些其他值。
2. nodeName和tagName
当然,差异就体现在它们的名字上,但确实有些微妙。
- tagName 属性仅适用于 Element 节点。
- nodeName 是为任意 Node 定义的:
- 对于元素,它的意义与 tagName 相同。
- 对于其他节点类型(text,comment 等),它拥有一个对应节点类型的字符串。
标签名称始终是大写的,除非在XML模式下
浏览器有两种处理文档(document)的模式:HTML 和 XML。通常,HTML 模式用于网页。只有在浏览器接收到带有 header Content-Type: application/xml+xhtml 的 XML-document 时,XML 模式才会被启用。
在 HTML 模式下,tagName/nodeName 始终是大写的:它是 BODY,而不是 <body> 或 <BoDy>。
在 XML 模式中,大小写保持为“原样”。如今,XML 模式很少被使用。
3. innerHTML
innerHTML 属性允许将元素中的 HTML 获取为字符串形式。
我们也可以修改它。因此,它是更改页面最有效的方法之一。
如果
innerHTML将一个<script>标签插入到 document 中 — 它会成为 HTML 的一部分,但是不会执行。
小心:“innerHTML+=” 会进行完全重写
即原来的内容会重新加载。
4. outerHTML
功能和 innerHTML类似,但是它改变了标签本身。
5. nodeValue/data:文本节点内容
innerHTML 属性仅对元素节点有效。
其他节点类型,例如文本节点,具有它们的对应项:nodeValue 和 data 属性。这两者在实际使用中几乎相同,只有细微规范上的差异。因此,我们将使用 data,因为它更短。
6. textContent:纯文本
textContent 提供了对元素内的 文本 的访问权限:仅文本,去掉所有 <tags>。可以利用此修改标签内的文本内容
7. “hidden”属性
从技术上来说,hidden 与 style="display:none" 做的是相同的事。但 hidden 写法更简洁。
1.6 特性和属性
DOM 属性和方法的行为就像常规的 Javascript 对象一样:
- 它们可以有很多值。
- 它们是大小写敏感的(要写成
elem.nodeType,而不是elem.NoDeTyPe)。
1. 特性
在 HTML 中,标签可能拥有特性(attributes)。当浏览器解析 HTML 文本,并根据标签创建 DOM 对象时,浏览器会辨别 标准的 特性并以此创建 DOM 属性。
请注意,一个元素的标准的特性对于另一个元素可能是未知的。
当然。所有特性都可以通过使用以下方法进行访问:
elem.hasAttribute(name)— 检查特性是否存在。elem.getAttribute(name)— 获取这个特性值。elem.attributes()— 读取所有特性。属于内建 Attr 类的对象的集合,具有name和value属性。elem.setAttribute(name, value)— 设置这个特性值。elem.removeAttribute(name)— 移除这个特性。
HTML 特性有以下几个特征:
- 它们的名字是大小写不敏感的(
id与ID相同)。 - 它们的值总是字符串类型的。
2. 属性—特性同步
一个标准的特性被改变,对应的属性也会自动更新,(除了几个特例)反之亦然。
let input = document.querySelector('input');
// 特性 => 属性
input.setAttribute('value', 'text');
alert(input.value); // text
// 这个操作无效,属性 => 特性
input.value = 'newValue';
alert(input.getAttribute('value')); // text(没有被更新!)但是我们可以在屏幕的显示上看到值已经被修改。
这个“功能”在实际中会派上用场,因为用户行为可能会导致 value 的更改,然后在这些操作之后,如果我们想从 HTML 中恢复“原始”值,那么该值就在特性中。
属性和特性的区别,属性是DOM对应对象上的属性,特性是HTML包含的特性。
3. 特性冲突
如果开发者自定义的特性在未来被引入到标准的特性中,那么就会产生冲突。所有以 “data-” 开头的特性均被保留供程序员使用。它们可在 dataset 属性中使用。
例如,如果一个 elem 有一个名为 "data-about" 的特性,那么可以通过 elem.dataset.about 取到它。
<body data-about="Elephants">
<script>
alert(document.body.dataset.about); // Elephants
</script>像 data-order-state 这样的多词特性可以以驼峰式进行调用:dataset.orderState。
1.7 DOM修改
1. 创建一个元素
**document.createElement(tag)**:创建一个元素节点
**document.createTextNode(text)**:创建一个文本节点
上面只是在JS中创建一个DOM对象,但是在HTML中我们还无法看到。
在node节点位置上插入创建的节点:
node.append(...nodes or strings)—— 在node末尾 插入节点或字符串,node.prepend(...nodes or strings)—— 在node开头 插入节点或字符串,node.before(...nodes or strings)—— 在node前面 插入节点或字符串,node.after(...nodes or strings)—— 在node后面 插入节点或字符串,node.replaceWith(...nodes or strings)—— 将node替换为给定的节点或字符串。

当我们插入的是字符串时,它会以”文本形式“插入,而不是“HTML代码”插入,如果写的时HTML代码也会被转义。
2. insertAdjacentHTML/Text/Element
在上面中,如果我们就想像innerHTML一样使用,为此,我们可以使用另一个非常通用的方法:elem.insertAdjacentHTML(where, html)。
该方法的第一个参数是代码字(code word),指定相对于 elem 的插入位置。必须为以下之一:
"beforebegin"— 将html插入到elem前插入,"afterbegin"— 将html插入到elem开头,"beforeend"— 将html插入到elem末尾,"afterend"— 将html插入到elem后。

这个方法有两个兄弟:
elem.insertAdjacentText(where, text)— 语法一样,但是将text字符串“作为文本”插入而不是作为 HTML,elem.insertAdjacentElement(where, elem)— 语法一样,但是插入的是一个元素。
它们的存在主要是为了使语法“统一”。实际上,大多数时候只使用 insertAdjacentHTML。因为对于元素和文本,我们有 append/prepend/before/after 方法 — 它们也可以用于插入节点/文本片段,但写起来更短。
3. 节点移除
想要移除一个节点,可以使用 node.remove()。
请注意:如果我们要将一个元素 移动 到另一个地方,则无需将其从原来的位置中删除。
所有插入方法都会自动从旧位置删除该节点。
<div id="first">First</div>
<div id="second">Second</div>
<script>
// 无需调用 remove
second.after(first); // 获取 #second,并在其后面插入 #first
</script>4. 克隆节点
调用 elem.cloneNode(true) 来创建元素的一个“深”克隆 — 具有所有特性(attribute)和子元素。如果我们调用 elem.cloneNode(false),那克隆就不包括子元素。
5. DocumentFragment
DocumentFragment 是一个特殊的 DOM 节点,用作来传递节点列表的包装器(wrapper)。我们可以向其附加其他节点,但是当我们将其插入某个位置时,则会插入其内容。
// TODO,感觉没什么用
6. 过时的insert/remove方法
parentElem.appendChild(node):将 node 附加为 parentElem 的最后一个子元素。
parentElem.insertBefore(node, nextSibling):在 parentElem 的 nextSibling 前插入 node。
parentElem.replaceChild(node, oldChild):将 parentElem 的后代中的 oldChild 替换为 node。
parentElem.removeChild(node):从 parentElem 中删除 node(假设 node 为 parentElem 的后代)。
7. document.write
同样,这也是一种过时的方法。这个方法适用于页面解析前,如果在页面解析后那么就会覆盖所有内容。因为它不涉及修改DOM,所以运行速度出奇的快
1.8 样式和类
通常有两种设置元素样式的方式:
- 在 CSS 中创建一个类,并添加它:
<div class="..."> - 将属性直接写入
style:<div style="...">。
相较于style的方式,我们更加倾向于class的方式,只有当class无法处理的时候我们才会选择style。
1. className和classList
更改类时JS中十分常见的操作,由于class即使DOM的属性又是JS的保留字,所以在很久以前,class不能作为对象的属性,但是现在这个限制不存在了。正是由于这远古的原因在引入了className。
如果我们对className进行赋值,它会替换类中的整个字符串。
elem.classList 是一个特殊的对象(可迭代),它具有 add/remove/toggle 单个类的方法。
classList 的方法:
elem.classList.add/remove(class)— 添加/移除类。elem.classList.toggle(class)— 如果类不存在就添加类,存在就移除它。elem.classList.contains(class)— 检查给定类,返回true/false。
2. 元素样式
对于多词(multi-word)属性,使用驼峰式 camelCase,所有的短横线之后的字母都会被转为大写。
比如前缀属性:-moz-border-radius 它会被转为 MozBorderRadius。
3. 样式重置
如果我们需要移除某一个样式,我们应该为其赋值为空字符串,不能选择删除属性。
注意 style 对象是一个只读的,我们不能像赋值一样对其直接修改,想要以字符串的形式设置完整的样式,可以使用特殊属性 style.cssText。
4. 单位
我们不应该将 elem.style.top 设置为 10,而应将其设置为 10px。否则设置会无效:
5. 计算样式
上面讲述的是修改样式,如果读取嘞?这样吗?
document.body.style.color这样是读取不出来的任何内容。这是因为:style 属性仅对 “style” 特性(attribute)值起作用,而没有任何 CSS 级联(cascade)。
读取的正确姿势:
getComputedStyle(element, [pseudo])element:需要被读取样式值的元素。pseudo:伪元素(如果需要),例如::before。空字符串或无参数则意味着元素本身。
- 计算 (computed) 样式值是所有 CSS 规则和 CSS 继承都应用后的值,这是 CSS 级联(cascade)的结果。它看起来像
height:1em或font-size:125%。 - 解析 (resolved) 样式值是最终应用于元素的样式值值。诸如
1em或125%这样的值是相对的。浏览器将使用计算(computed)值,并使所有单位均为固定的,且为绝对单位,例如:height:20px或font-size:16px。对于几何属性,解析(resolved)值可能具有浮点,例如:width:50.5px。
可以使用 CSS 伪类
:visited对被访问过的链接进行着色。但getComputedStyle没有给出访问该颜色的方式,因为如果给出了,那么就可以通过检查样式来确定用户是否访问了某个链接。此外,在CSS中也有类似的限制,即禁止在:visited中应用更改几何形状的样式。这是为了确保一个不好的页面无法测试链接是否被访问,进而窥探隐私。
1.9 元素大小和滚动
// TODO
1.10 Window大小和滚动
// TODO
1.11 坐标
2. 事件
鼠标事件
click—— 当鼠标点击一个元素时(触摸屏设备会在点击时生成)。contextmenu—— 当鼠标右键点击一个元素时。mouseover/mouseout—— 当鼠标指针移入/离开一个元素时。mousedown/mouseup—— 当在元素上按下/释放鼠标按钮时。mousemove—— 当鼠标移动时。
键盘事件
keydown和keyup—— 当按下和松开一个按键时。
表单(form)元素事件:
submit—— 当访问者提交了一个<form>时。focus—— 当访问者聚焦于一个元素时,例如聚焦于一个<input>。
Document 事件:
DOMContentLoaded—— 当 HTML 的加载和处理均完成,DOM 被完全构建完成时。
CSS 事件:
transitionend—— 当一个 CSS 动画完成时。
2.1. 事件简介
1. 事件处理器
HTML特性
处理程序可以设置在 HTML 中名为 on<event> 的特性(attribute)中。
<input value="Click me" onclick="alert('Click!')" type="button">DOM属性
我们可以使用 DOM 属性(property)on<event> 来分配处理程序。
<input id="elem" type="button" value="Click me">
<script>
elem.onclick = function() {
alert('Thank you');
};
</script>2. 访问元素:this
<button onclick="alert(this.innerHTML)">Click me</button>3. 可能出现的错误
在HTML特性进行事件处理时,注意函数具有括号。
如果我们使用 setAttribute 的方式,注意下面的方式时错误的:
// 点击 <body> 将产生 error,
// 因为特性总是字符串的,函数变成了一个字符串
document.body.setAttribute('onclick', function() { alert(1) });4. addEventListener
上面的处理方式的根本问题是,我们不能为一个事件分配多个处理程序。
Web 标准的开发者很早就了解到了这一点,并提出了一种使用特殊方法 addEventListener 和 removeEventListener 来管理处理程序的替代方法。它们没有这样的问题。
element.addEventListener(event, handler[, options]);event事件名,例如:
"click"。handler处理程序。
options具有以下属性的附加可选对象:
once:如果为true,那么会在被触发后自动删除监听器。capture:事件处理的阶段,我们稍后将在 冒泡和捕获 一章中介绍。由于历史原因,options也可以是false/true,它与{capture: false/true}相同。passive:如果为true,那么处理程序将不会调用preventDefault(),我们稍后将在 浏览器默认行为 一章中介绍。
要移除处理程序,可以使用 removeEventListener:
element.removeEventListener(event, handler[, options]);移除需要相同的函数:
如果传入的函数引用不同,那么就算传入的内容相同,也无法进行正确的移除,所以需要将函数存储在一个变量中。
我们可以同时使用 DOM 属性和
addEventListener来设置处理程序。但通常我们只使用其中一种方式。
对于某些事件,只能通过addEventListener 设置处理程序。比如:DOMContentLoaded。
如果某个元素添加了多个监听器,那么事件的响应顺序和设置顺序相同。
5. 事件对象
当事件发生时,浏览器会创建一个 event 对象,将详细信息放入其中,并将其作为参数传递给处理程序。
event.type
事件类型,比如 “click”。event.currentTarget
处理事件的元素。这与 this 相同,除非处理程序是一个箭头函数,或者它的 this 被绑定到了其他东西上,之后我们就可以从event.currentTarget 获取元素了。event.clientX / event.clientY
指针事件(pointer event)的指针的窗口相对坐标。
HTML特性方式也可以。
6. 对象处理程序
上面我们都是为事件处理器分配一个函数,实际上我们也可以分配一个对象,当事件发生时就会调用该对象的 handleEvent 方法。
2.2. 冒泡和捕获
当一个事件发生在一个元素上,它会首先运行在该元素上的处理程序,然后运行其父元素上的处理程序,然后一直向上到其他祖先上的处理程序。
几乎所有的事件都会冒泡,但是也有例外,例如 focus
1. event.target
父元素上的处理程序始终可以获取事件实际发生位置的详细信息。
引发事件的那个嵌套层级最深的元素被称为目标元素,可以通过 event.target 访问。
注意与 this(=event.currentTarget)之间的区别:
event.target—— 是引发事件的“目标”元素,它在冒泡过程中不会发生变化。this—— 是“当前”元素,其中有一个当前正在运行的处理程序。
2. 停止冒泡
用于停止冒泡的方法是 event.stopPropagation(),但是这只能停止一个。event.stopImmediatePropagation(),可以让所有事件停止冒泡。
不要在没有需要的的情况下停止冒泡
3. 捕获
DOM 事件标准描述了事件传播的 3 个阶段:
- 捕获阶段(Capturing phase)—— 事件(从 Window)向下走近元素。
- 目标阶段(Target phase)—— 事件到达目标元素。
- 冒泡阶段(Bubbling phase)—— 事件从元素上开始冒泡。
为了在捕获阶段捕获事件,我们需要将处理程序的 capture 选项设置为 true:
elem.addEventListener(..., {capture: true})
// 或者,用 {capture: true} 的别名 "true"
elem.addEventListener(..., true)capture 选项有两个可能的值:
- 如果为
false(默认值),则在冒泡阶段设置处理程序。 - 如果为
true,则在捕获阶段设置处理程序。
2.3 事件委托
如果我们有许多以类似方式处理的元素,那么就不必为每个元素分配一个处理程序 —— 而是将单个处理程序放在它们的共同祖先上。

在这样一个图中,如果想实现点击某一个格子,从而使该格子高亮,我们不必为每个格子添加事件,只需要为外层的table添加一个事件处理器,再根据传入的 event 对象判断是哪一个格子。但是问题在于,如果我们点击不是该格子,而是里面的元素(如文本),这时我们可以使用 closest 来寻找最近的td。
为什么我们需要事件委托,正如上面的例子中,如果格子变多,那么由于每个格子都需要创建对应的对象进行事件处理,创建的对象越多,页面的性能就越差,使用事件委托,我们可以极大的减少对象创建。
事件委托的原理就是利用事件冒泡。
1. 委托示例:标记中的行为
当我们需要为三个按钮分配三个不同的事件,可能最先想到的就是依次设置点击事件,但是有一个更优雅的解决方案。我们可以为整个菜单添加一个处理程序。
// TODO
2. “行为”模式
行为模式分为两个部分:
- 我们将自定义特性添加到描述其行为的元素。
- 用
文档范围级的处理程序追踪事件,如果事件发生在具有特定特性的元素上 —— 则执行行为(action)。
计数器
Counter: <input type="button" value="1" data-counter>
One more counter: <input type="button" value="2" data-counter>
<script>
document.addEventListener('click', function(event) {
if (event.target.dataset.counter != undefined) { // 如果这个特性存在...
event.target.value++;
}
});
</script>代码中,为整个document设置事件,点击其子元素且包含设置的特性,则触发修改,事件能够响应的根本原理就是事件冒泡,而 target始终指向的是 点击的元素。
切换器
<button data-toggle-id="subscribe-mail">
Show the subscription form
</button>
<form id="subscribe-mail" hidden>
Your mail: <input type="email">
</form>
<script>
document.addEventListener('click', function(event) {
let id = event.target.dataset.toggleId;
if (!id) return;
let elem = document.getElementById(id);
elem.hidden = !elem.hidden;
});
</script>2.4 浏览器默认行为
许多事件会自动触发浏览器执行某些行为。
例如:
- 点击一个链接 —— 触发导航(navigation)到该 URL。
- 点击表单的提交按钮 —— 触发提交到服务器的行为。
- 在文本上按下鼠标按钮并移动 —— 选中文本。
有时候我们希望使用浏览器不去执行这些默认行为,或者替换成自己的处理程序。
1. 阻止浏览器行为
- 主流的方式是使用
event对象。有一个event.preventDefault()方法。 - 如果处理程序是使用
on<event>(而不是addEventListener)分配的,那返回false也同样有效。其它情况返回没有意义。
2. 处理程序选项“passive”
浏览器的默认行为通常发生在处理程序处理后,但是这样就会造成不必要的延迟和抖动。
addEventListener 的可选项 passive: true 向浏览器发出信号,表明处理程序将不会调用 preventDefault()。
3. event.defaultPrevented
如果默认行为被阻止,那么 event.defaultPrevented 属性为 true,否则为 false。
2.5 创建自定义事件
1. 事件构造器
内建事件类形成一个层次结构(hierarchy),类似于 DOM 元素类。根是内建的 Event 类。
我们可以像这样创建 Event 对象:
let event = new Event(type[, options]);参数:
type —— 事件类型,可以是像这样
"click"的字符串,或者我们自己的像这样"my-event"的参数。options —— 具有两个可选属性的对象:
bubbles: true/false—— 如果为true,那么事件会冒泡。cancelable: true/false—— 如果为true,那么“默认行为”就会被阻止。稍后我们会看到对于自定义事件,它意味着什么。
默认情况下,以上两者都为 false:
{bubbles: false, cancelable: false}。
2. dispatchEvent
事件对象被创建后,我们应该使用 elem.dispatchEvent(event) 调用在元素上“运行”它。
event.isTrusted
有一种方法可以区分“真实”用户事件和通过脚本生成的事件。
对于来自真实用户操作的事件,event.isTrusted 属性为 true,对于脚本生成的事件,event.isTrusted 属性为 false。
3. Event子类
这是一个摘自于 UI 事件规范 的一个简短的 UI 事件类列表:
UIEventFocusEventMouseEventWheelEventKeyboardEvent- …
4. 自定义事件
Event对象的第二个参数,除了一些可选项,还可以自定义一些属性,理论上讲我们可以创建任何属性,但是 CustomEvent 提供了特殊的 detail 字段,以避免与其他事件属性的冲突。
5. preventDefault()
如果自定义的事件被 preventDefault 那么当我们调用 dispatchEvent(event) 就会返回一个false的结果。
6. 事件中的事件是同步的
通常事件是在队列中处理的。一般来说,当有在执行一个事件的时候,如果另一个事件被触发,那么第二个事件就会排入队列中,只有等待第一个事件执行完之后,第二个事件才会进行处理。
值得注意的例外情况就是,一个事件是在另一个事件中发起的。例如使用 dispatchEvent。这类事件将会被立即处理,即在新的事件处理程序被调用之后,恢复到当前的事件处理程序。如果我们就像让事件顺序执行,可以将被调用的事件放在事件处理器的末尾行,或者使用一个定时函数。
3. UI事件
3.1 鼠标事件
1. 鼠标事件类型
mousedown/mouseup
在元素上点击/释放鼠标按钮。mouseover/mouseout
鼠标指针从一个元素上移入/移出。mousemove
鼠标在元素上的每个移动都会触发此事件。click
如果使用的是鼠标左键,则在同一个元素上的 mousedown 及 mouseup 相继触发后,触发该事件。dblclick
在短时间内双击同一元素后触发。如今已经很少使用了。contextmenu
在鼠标右键被按下时触发。还有其他打开上下文菜单的方式,例如使用特殊的键盘按键,在这种情况下它也会被触发,因此它并不完全是鼠标事件。
由于 click和contextmenu都会先引起 mousedown 和 mouseup 事件。我们可以通过 event.button 的值来进行区分是左击还是右击。
event.button 的所有可能值如下:
| 鼠标按键状态 | event.button |
|---|---|
| 左键 (主要按键) | 0 |
| 中键 (辅助按键) | 1 |
| 右键 (次要按键) | 2 |
| X1 键 (后退按键) | 3 |
| X2 键 (前进按键) | 4 |
另外,还有一个 event.buttons 属性,其中以整数的形式存储着当前所有按下的鼠标按键,每个按键一个比特位。在实际开发中,很少会用到这个属性,如果有需要的话,你可以在 MDN 中找到更多细节。
event.which
一些老代码可能会使用 event.which 属性来获得按下的按键。这是一个古老的非标准的方式,具有以下可能值:
event.which == 1—— 鼠标左键,event.which == 2—— 鼠标中键,event.which == 3—— 鼠标右键。
现在,event.which 已经被弃用了,不应再使用它。
2. 组合键:shift, alt, ctrl, meta
所有的鼠标事件都包含有关按下的组合键的信息。
事件属性:
shiftKey:ShiftaltKey:Alt(或对于 Mac 是 Opt)ctrlKey:CtrlmetaKey:对于 Mac 是 Cmd
<button id="button">Alt+Shift+Click on me!</button>
<script>
button.onclick = function(event) {
if (event.altKey && event.shiftKey) {
alert('Hooray!');
}
};
</script>Mac
在Mac设备上,我们通常使用 cmd 代替 ctrl ,尽管mac上有 ctrl 但是 ctrl 键和其它键组合可能会有其它快捷方式,比如 Ctrl+click 在mac上会解释成 contextmenu。这就导致我们的程序在事件检查时,应该是 if (event.ctrlKey || event.metaKey)
移动设备
键盘组合式工作流的一个补充,通常在移动设备中,除非有外置键盘否则快捷方式都会失效,所以我们必须考虑没有快捷方式的情况。
3. 坐标
所有的鼠标事件都提供了两种形式的坐标:
- 相对于窗口的坐标:
clientX和clientY。随着页面滚动而改变。 - 相对于文档的坐标:
pageX和pageY。不会随着页面滚动而改变。
4. 防止在鼠标按下时的选择
双击鼠标会有副作用,在某些界面中可能会出现干扰:它会选择文本。我们可以使用阻止默认事件。
防止复制
可以在 oncopy 事件中阻止默认事件。
3.2 鼠标移动
1. mouseover/mouseout
对于这两个事件,它的event对象有一个特殊的属性 relatedTarget ,此属性是对 target 的补充。我们只需要记住,无论是mouseover还是mouseouttarget事件,其target都是上图的div,至于 relatedTarget ,如果 mouseover 事件,那么 relatedTarget 是移入前的元素,相对的,mouseout 则是移到的那个元素。如果 relatedTarget 说明移入前在窗口外,或者移动到窗口外。
2. 跳过元素
当我们移动的鼠标过快是,是有可能跳过某些元素,这听起来有些像“称它不注意”,其实这是一个对性能有好处的,因为当我们移动到目标元素时中间时,我们并不是想要检查每一个移入和移除的过程。
但是有一点我们需要注意,如果 mouseover 被触发了,那么 mouseout 也一定会被触发。
3. mouseenter/mouseleave
事件 mouseenter/mouseleave 类似于 mouseover/mouseout。它们在鼠标指针进入/离开元素时触发。
但是有两个重要的区别:
- 元素内部与后代之间的转换不会产生影响。
- 事件
mouseenter/mouseleave不会冒泡。
所谓不会冒泡,即当从父元素移入到子元素时,则不会识别为鼠标的移入移出。
4. 事件委托
由于事件 mouseenter/mouseleave 不会冒泡,因此我们不能使用它们进行事件委托
3.3 鼠标拖放事件
在现代 HTML 标准中有一个 关于拖放的部分,其中包含了例如 dragstart 和 dragend 等特殊事件。
1. 拖放算法
- 在
mousedown上 —— 根据需要准备要移动的元素(也许创建一个它的副本,向其中添加一个类或其他任何东西)。 - 然后在
mousemove上,通过更改position:absolute情况下的left/top来移动它。 - 在
mouseup上 —— 执行与完成的拖放相关的所有行为。
注意拖动是具有默认事件的,比如如果拖动图片会出现禁止拖动的效果。
// TODO
3.4 指针事件
最开始的时候只有鼠标事件,但是随着智能机的普及出现了多点触摸,这时候鼠标事件无法满足我们的要求了,现在更是有触控笔等等,它们都有属于自己的特性,如果每一个都进行维护就显得有些笨重了。这时候引入了指针事件,它为各种指针输入设备提供了一套统一的事件。
1. 指针事件类型
指针事件的命名方式和鼠标事件类似:
| 指针事件 | 类似的鼠标事件 |
|---|---|
pointerdown |
mousedown |
pointerup |
mouseup |
pointermove |
mousemove |
pointerover |
mouseover |
pointerout |
mouseout |
pointerenter |
mouseenter |
pointerleave |
mouseleave |
pointercancel |
- |
gotpointercapture |
- |
lostpointercapture |
我们可以把代码中的 mouse<event> 都替换成 pointer<event>,程序仍然正常兼容鼠标设备。
2. 指针事件属性
指针事件具备和鼠标事件完全相同的属性,包括 clientX/Y 和 target 等,以及一些其他属性:
pointerId—— 触发当前事件的指针唯一标识符。浏览器生成的。使我们能够处理多指针的情况,例如带有触控笔和多点触控功能的触摸屏(下文会有相关示例)。
pointerType—— 指针的设备类型。必须为字符串,可以是:“mouse”、“pen” 或 “touch”。我们可以使用这个属性来针对不同类型的指针输入做出不同响应。
isPrimary—— 当指针为首要指针(多点触控时按下的第一根手指)时为true。
有些指针设备会测量接触面积和点按压力(例如一根手指压在触屏上),对于这种情况可以使用以下属性:
width—— 指针(例如手指)接触设备的区域的宽度。对于不支持的设备(如鼠标),这个值总是1。height—— 指针(例如手指)接触设备的区域的长度。对于不支持的设备,这个值总是1。pressure—— 触摸压力,是一个介于 0 到 1 之间的浮点数。对于不支持压力检测的设备,这个值总是0.5(按下时)或0。tangentialPressure—— 归一化后的切向压力(tangential pressure)。tiltX,tiltY,twist—— 针对触摸笔的几个属性,用于描述笔和屏幕表面的相对位置。
大多数设备都不支持这些属性,因此它们很少被使用。如果你需要使用它们,可以在 规范文档 中查看更多有关它们的详细信息。
3. 多点触控
多点触控(用户在手机或平板上同时点击若干个位置,或执行特殊手势)是鼠标事件完全不支持的功能之一。
- 第一个手指触摸:
pointerdown事件触发,isPrimary=true,并且被指派了一个pointerId。
- 第二个和后续的更多个手指触摸(假设第一个手指仍在触摸):
pointerdown事件触发,isPrimary=false,并且每一个触摸都被指派了不同的pointerId。
4. 事件:pointercancel
pointercancel 事件将会在一个正处于活跃状态的指针交互由于某些原因被中断时触发。也就是在这个事件之后,该指针就不会继续触发更多事件了。
导致指针中断的可能原因如下:
- 指针设备硬件在物理层面上被禁用。
- 设备方向旋转(例如给平板转了个方向)。
- 浏览器打算自行处理这一交互,比如将其看作是一个专门的鼠标手势或缩放操作等。
阻止浏览器的默认行为来防止 pointercancel 触发。
我们需要做两件事:
- 阻止原生的拖放操作发生:
- 正如我们在 鼠标拖放事件 中描述的那样,我们可以通过设置
ball.ondragstart = () => false来实现这一需求。 - 这种方式也适用于鼠标事件。
- 正如我们在 鼠标拖放事件 中描述的那样,我们可以通过设置
- 对于触屏设备,还有其他和触摸相关的浏览器行为(除了拖放)。为了避免它们所引发的问题:
- 我们可以通过在 CSS 中设置
#ball { touch-action: none }来阻止它们。 - 之后我们的代码便可以在触屏设备中正常工作了。
- 我们可以通过在 CSS 中设置
5. 指针捕获
elem.setPointerCapture(pointerId) —— 将给定的 pointerId 绑定到 elem。在调用之后,所有具有相同 pointerId 的指针事件都将 elem 作为目标(就像事件发生在 elem 上一样),无论这些 elem 在文档中的实际位置是什么。
绑定会在以下情况下被移除:
- 当
pointerup或pointercancel事件出现时,绑定会被自动地移除。 - 当
elem被从文档中移除后,绑定会被自动地移除。 - 当
elem.releasePointerCapture(pointerId)被调用,绑定会被移除。
比如:元素块内有一个滑动拖块,当我们拖动时,如果拖到元素外,就会断开拖动事件,如果我们为整个document绑定拖动事件,那么就可能引起其它的元素的拖动函数。
指针捕获提供了一种将 pointermove 绑定到 thumb 并避免其他此类问题发生的方式:
- 我们可以在
pointerdown事件的处理程序中调用thumb.setPointerCapture(event.pointerId), - 这样接下来在
pointerup/cancel之前发生的所有指针事件都会被重定向到thumb上。 - 当
pointerup发生时(拖动完成),绑定会被自动移除,我们不需要关心它。
还有两个相关的指针捕获事件:
gotpointercapture会在一个元素使用setPointerCapture来启用捕获后触发。lostpointercapture会在捕获被释放后触发:其触发可能是由于releasePointerCapture的显式调用,或是pointerup/pointercancel事件触发后的自动调用。
3.5 键盘:keydown/keyup
1. keydown/keyup
当一个按键被按下时,会触发 keydown 事件,而当按键被释放时,会触发 keyup 事件。
event.code 和 event.key
事件对象的 key 属性允许获取字符,而事件对象的 code 属性则允许获取“物理按键代码”。
尽管大多时候 code 和 key 的内容相同,但是有些时候code的内容更加精确,比如 shift 按键,code会明确告知是键盘左边的shift还是右边的shift。此外 key 获取是一个字符,它会随着语言的改变而改变,并且有些键盘之间相同的位置但是字符也有所不同,所以使用code更加合适。
2. 自动重复
如果按下一个键足够长的时间,它就会开始“自动重复”:keydown 会被一次又一次地触发,然后当按键被释放时,我们最终会得到 keyup。因此,有很多 keydown 却只有一个 keyup 是很正常的。
对于由自动重复触发的事件,event 对象的 event.repeat 属性被设置为 true。
3. 默认行为
默认行为各不相同,因为键盘可能会启动许多可能的东西。
例如:
- 出现在屏幕上的一个字符(最明显的结果)。
- 一个字符被删除(Delete 键)。
- 滚动页面(PageDown 键)。
- 浏览器打开“保存页面”对话框(Ctrl+S)
- ……等。
阻止对 keydown 的默认行为可以取消大多数的行为,但基于 OS 的特殊按键除外。例如,在 Windows 中,Alt+F4 会关闭当前浏览器窗口。并且无法通过在 JavaScript 中阻止默认行为来阻止它。
例如,下面的这个 <input> 期望输入的内容为一个电话号码,因此它不会接受除数字,+,() 和 - 以外的按键:
<script>
function checkPhoneKey(key) {
return (key >= '0' && key <= '9') || key == '+' || key == '(' || key == ')' || key == '-';
}
</script>
<input onkeydown="return checkPhoneKey(event.key)" placeholder="Phone, please" type="tel">遗存
过去曾经有一个 keypress 事件,还有事件对象的 keyCode、charCode 和 which 属性。
大多数浏览器对它们都存在兼容性问题,以致使该规范的开发者不得不弃用它们并创建新的现代的事件(本文上面所讲的这些事件),除此之外别无选择。旧的代码仍然有效,因为浏览器还在支持它们,但现在完全没必要再使用它们。
3.6 滚动
scroll 事件允许对页面或元素滚动作出反应。
防止滚动
我们不能通过在 onscroll 监听器中使用 event.preventDefault() 来阻止滚动,因为它会在滚动发生之后才触发。
但是我们可以在导致滚动的事件上,例如在 pageUp 和 pageDown 的 keydown 事件上,使用 event.preventDefault() 来阻止滚动。
4. 表单控件
4.1.表单属性和方法
1. 访问
文档中的表单是特殊集合 document.forms 的成员。
这就是所谓的“命名的集合”:既是被命名了的,也是有序的。我们既可以使用名字,也可以使用在文档中的编号来获取表单。
document.forms.my - name="my" 的表单
document.forms[0] - 文档中的第一个表单可能会有多个名字相同的元素,这种情况经常在处理单选按钮中出现。
在这种情况下,form.elements[name] 将会是一个集合
form.elements.age[0]; form表单中名为age的元素集合的第一个Fieldset作为“子表单”
一个表单内会有一个或多个 <fieldset> 元素。它们也具有 elements 属性,该属性列出了 <fieldset> 中的表单控件。
更简短的表示方式:form.name
一般情况下,我们是通过form.elements.login 这种方式访问login,其实它支持更加简短的方式 form.login。
我们是可以通过上面的方式修改表单的控件的 name 。
2. 反向引用
对于任何元素,其对应的表单都可以通过 element.form 访问到。因此,表单引用了所有元素,元素也引用了表单。
3. 表单元素
input 和 textarea
我们可以通过 input.value(字符串)或 input.checked(布尔值)来访问复选框(checkbox)中的它们的 value。
使用
textarea.value而不是textarea.innerHTML,尽管后者可以,但是正如前面所说,这是不安全的。
select 和 option
一个 <select> 元素有 3 个重要的属性:
select.options——<option>的子元素的集合,select.value—— 当前所选择的<option>的value,select.selectedIndex—— 当前所选择的<option>的编号。
它们提供了三种为 <select> 设置 value 的不同方式:
- 找到对应的
<option>元素,并将option.selected设置为true。 - 将
select.value设置为对应的value。 - 将
select.selectedIndex设置为对应<option>的编号。
4. new Option
创建一个 <option> 元素:
option = new Option(text, value, defaultSelected, selected);参数:
text——<option>中的文本,value——<option>的value,defaultSelected—— 如果为true,那么selectedHTML-特性(attribute)就会被创建,selected—— 如果为true,那么这个<option>就会被选中。
<option> 元素具有以下属性:
option.selected<option>是否被选择。option.index<option>在其所属的<select>中的编号。option.text<option>的文本内容(可以被访问者看到)。
4.2. 聚焦
1. focus/blur事件
当元素聚焦时,会触发 focus 事件,当元素失去焦点时,会触发 blur 事件。
通常,我们在blur事件中进行输入校验
请注意,我们无法通过在 onblur 事件处理程序中调用 event.preventDefault() 来“阻止失去焦点”,因为 onblur 事件处理程序是在元素失去焦点 之后 运行的。
Javascript导致的焦点丢失
其中之一就是用户点击了其它位置。当然 JavaScript 自身也可能导致焦点丢失,例如:
- 一个
alert会将焦点移至自身,因此会导致元素失去焦点(触发blur事件),而当alert对话框被取消时,焦点又回重新回到原元素上(触发focus事件)。 - 如果一个元素被从 DOM 中移除,那么也会导致焦点丢失。如果稍后它被重新插入到 DOM,焦点也不会回到它身上。
2. 允许在任何元素上聚焦:tabindex
默认情况下,很多元素不支持聚焦。
列表(list)在不同的浏览器表现不同,但有一件事总是正确的:focus/blur 保证支持那些用户可以交互的元素:<button>,<input>,<select>,<a> 等。
另一方面,为了格式化某些东西而存在的元素像 <div>,<span> 和 <table> —— 默认是不能被聚焦的。elem.focus() 方法不适用于它们,并且 focus/blur 事件也绝不会被触发。
使用 HTML-特性(attribute)tabindex 可以改变这种情况。任何具有 tabindex 特性的元素,都会变成可聚焦的。该特性的 value 是当使用 Tab(或类似的东西)在元素之间进行切换时,元素的顺序号。
这里有两个特殊的值:
tabindex="0"会使该元素被与那些不具有tabindex的元素放在一起。也就是说,当我们切换元素时,具有tabindex="0"的元素将排在那些具有tabindex ≥ 1的元素的后面。通常,它用于使元素具有焦点,但是保留默认的切换顺序。使元素成为与
<input>一样的表单的一部分。tabindex="-1"只允许以编程的方式聚焦于元素。Tab 键会忽略这样的元素,但是elem.focus()有效。
3. 事件委托
focus 和 blur 事件不会向上冒泡。
这里有两个解决方案。
- 方案一,有一个遗留下来的有趣的特性(feature):
focus/blur不会向上冒泡,但会在捕获阶段向下传播。 - 方案二,可以使用
focusin和focusout事件 —— 与focus/blur事件完全一样,只是它们会冒泡。
值得注意的是,方案二必须使用 elem.addEventListener 来分配它们,而不是 on<event>。
4.3 事件
1. change
当元素更改完成时,将触发 change 事件。
对于文本输入框,当其失去焦点时并且元素内容改变,就会触发 change 事件。
对于其它元素:select,input type=checkbox/radio,会在选项更改后立即触发 change 事件。
2. input
每当用户对输入值进行修改后,就会触发 input 事件。
当输入值更改后,就会触发
input事件。所以,我们无法使用event.preventDefault()—— 已经太迟了,不会起任何作用了。可以在onkeydown中阻止。
3. cut, copy, paste
行为可以被阻止。event.clipboardData 属性可以用于读/写剪贴板。
但是请注意,剪贴板是“全局”操作系统级别的。安全起见,大多数浏览器仅在特定的用户行为下,才允许对剪贴板进行读/写,例如在 onclick 事件处理程序中。
并且,除火狐(Firefox)浏览器外,所有浏览器都禁止使用 dispatchEvent 生成“自定义”剪贴板事件。
4.4 表单提交
提交表单时,会触发 submit 事件,它通常用于在将表单发送到服务器之前对表单进行校验,或者中止提交,并使用 JavaScript 来处理表单。
1. 事件:submit
提交表单主要有两种方式:
- 第一种 —— 点击
<input type="submit">或<input type="image">。 - 第二种 —— 在
input字段中按下 Enter 键。
submit 和 click 的关系
在输入框中使用 Enter 发送表单时,会在 <input type="submit"> 上触发一次 click 事件。
这很有趣,因为实际上根本没有点击。
2. 方法:submit
如果要手动将表单提交到服务器,我们可以调用 form.submit()。
这样就不会产生 submit 事件。这里假设如果开发人员调用 form.submit(),就意味着此脚本已经进行了所有相关处理。
5. 加载文档和其它资源
5.1 页面生命周期
HTML 页面的生命周期包含三个重要事件:
DOMContentLoaded—— 浏览器已完全加载 HTML,并构建了 DOM 树,但像<img>和样式表之类的外部资源可能尚未加载完成。load—— 浏览器不仅加载完成了 HTML,还加载完成了所有外部资源:图片,样式等。beforeunload/unload—— 当用户正在离开页面时。
每个事件都是有用的:
DOMContentLoaded事件 —— DOM 已经就绪,因此处理程序可以查找 DOM 节点,并初始化接口。load事件 —— 外部资源已加载完成,样式已被应用,图片大小也已知了。beforeunload事件 —— 用户正在离开:我们可以检查用户是否保存了更改,并询问他是否真的要离开。unload事件 —— 用户几乎已经离开了,但是我们仍然可以启动一些操作,例如发送统计数据。
1. DOMContentLoaded
在进行页面加载时,如果在文档中遇到<script> ,它会直接运行,之后才会继续构建DOM,这样做的原因时我们可能在脚本中修改DOM。
不会阻塞 DOMContentLoaded 的脚本
此规则有两个例外:
- 具有
async特性(attribute)的脚本不会阻塞DOMContentLoaded,稍后 我们会讲到。 - 使用
document.createElement('script')动态生成并添加到网页的脚本也不会阻塞DOMContentLoaded。
外部样式表不会影响 DOM,因此 DOMContentLoaded 不会等待它们。
但这里有一个陷阱。如果在样式后面有一个脚本,那么该脚本必须等待样式表加载完成。